
機械学習に興味にある方は、サポートベクターマシン(SVM)で検索する人も多いですよね。しかし、実際にサイトを見ると難しい数式があって、なかなか敷居が高いと感じる人も結構いるでしょう。
サポートベクターマシン(SVM)はAI(人工知能)の技術にかかせない機械学習アルゴリズムの一つです。アルゴリズムとは計算方法を指したもので、AI(人工知能)が流行する前からサポートベクターマシンは、とても有効な手法の一つでした。
この記事では、サポートベクターマシン(SVM)の仕組みを簡単に説明して、さらに、Pythonで実装するまでについて触れています。そこで今回は、サポートベクターマシン(SVM)を通して、学習がどのように行われていくのかを解説します。
サポートベクターマシン(SVM)とは

サポートベクトルマシン(SVM)とは、機械学習アルゴリズムの一つ。特に、データを分類する分野で強力なアルゴリズムです。
サポートベクターマシンに分類したいデータを与えるだけで、そのデータが何のデータなのかを教えてくれます。たとえば、犬の画像をサポートベクターマシンに読み込ませたときに、「この画像は犬ですよ」と教えてくれるようになります。
正解データが分かっているのになぜ学習をさせるのか、疑問に感じる人もいますよね。サポートベクターマシン(SVM)はこの正解データを利用して学習を行い、未知のデータをサポートベクターマシンに読み込ませ、分類できるようにします。
サポートベクターマシン(SVM)は、スマートフォンの顔認証などの画像認識や人の手書きの文字の認識などに使用されます。また、時系列データの予測にも活用することができ、売り上げの予測などのビジネスにも活用されます。
サポートベクターマシンと機械学習の関連性

サポートベクターマシン(SVM)は機械学習の手法です。機械学習とは、コンピューターに正解をプログラミングしていくのではなく、コンピューター自身が何か問題に対して、自分で考え、学習するプログラムのことです。
サポートベクターマシン(SVM)は、1963年に提案された手法で近年のAI(人工知能)の発展の前からある手法です。当時のニューラルネットワークは、勾配消失や過学習などの正しく学習できない問題がありました。(ニューラルネットワークとは脳の情報処理をまねした数学モデルのこと)
では、学習アルゴリズムが実際にどのように行われていくかを見ていきましょう。
サポートベクターマシン(SVM)は、画像データを線形分離することで画像認識を行います。線形分離とは、認識したい対象を直線または平面に分離することをいいます。
学習の流れを説明すると、サポートベクターマシン(SVM)は、画像データをニューラルネットワークに読み込ませます。ニューラルネットワークの出力は、教師を利用して正しい出力を求めますが、その際に画像データをちょうど直線で分けられるような出力になるように学習をします。さらに学習を行うと、直線の付近の画像データとの距離が最大になるように学習をすると、未知の画像データに対しても認識できるようになります。
このように、直線の付近のデータだけを学習に利用するので、サポートベクターマシン(SVM)は、非常に高速に学習できるようになりました。その結果として、画像認識の性能は飛躍的に上昇しました。
では、学習データが正解を出力するためにどのようにすればよいのか考えましょう。今回は分類問題を考えているので、下の図のように、入力データから赤丸と青丸が直線を通して分類できるとします。もしここで、この直線の数値を求めることができたら分類問題を解けたといえます。
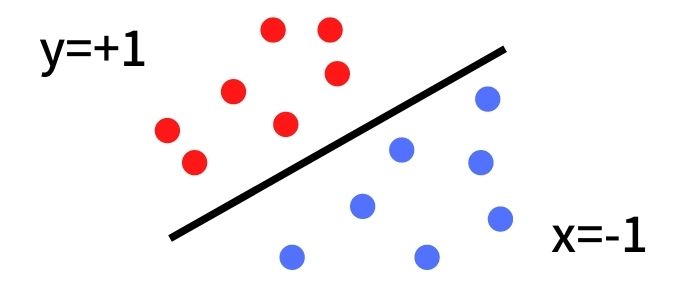
なぜなら、分類したいデータがこの直線の上にあるか、下にあるかで判断できるからです。この直線はデータを分類できれば良いのでいろいろな取り方がありますが、この直線付近のデータ同士がちょうど中間になるような重みを求めます。
この直線付近のデータのことをサポートベクトルと呼び、これが、サポートベクターマシン(SVM)の名前の由来です。
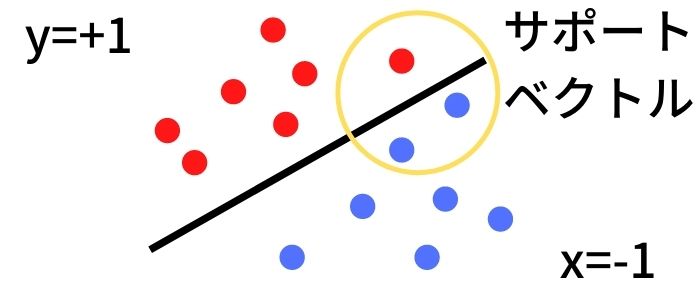
※詳しくはこちらの記事でも解説しています

実際の計算では、この直線付近のサポートベクトルだけを学習するだけなので、計算量は他の機械学習アルゴリズムに比べ少ないです。つまり、大量のデータがあるときに、それらをすべて学習するには時間がかかりすぎてしまいますが、サポートベクターマシン(SVM)は自動的に計算に必要な部分を抽出することで、短時間で学習が行えることがメリット。
サポートベクター回帰とは

回帰とはあるデータがどのように説明できるかをある関数に当てはめることをいいます。よく使われる例としては、データを直線に当てはめる例で、これを線形回帰といいます。
データを直線に当てはめることで何がメリットになるかというと、データの予測を行えるようになる点です。
今現在で分かっていることから、未来のデータを予測することができたらうれしいですよね。
サポートベクターマシン(SVM)はもともとデータを分類する直線をもとめる手法なので、線形回帰問題にも有効です。サポートベクターマシン(SVM)で回帰問題を解くことをサポートベクター回帰といいます。
学習の手法はサポートベクターマシン(SVM)と変わりありません。データが直線付近にあつまるときにその関係を求めることができます。サポートベクター回帰は、売り上げ予測など複数の要因から未来を予測したいときに利用されます。応用の幅は広く、マーケティング、為替の変動、天候、人口数など現実の社会で活用されているのだとか。
サポートベクターマシンをPythonで実装してみよう!その方法を解説

サポートベクターマシン(SVM)の学習は数多くの数学的な手法を使用してますが、Pythonでは、サポートベクターマシン(SVM)を計算してくれるsklearnというライブラリがあります。これにより、なんと20行以下のプログラムで実装でき、学習データと正解データの組み合わせを用意すればだれでも簡単にサポートベクターマシン(SVM)を使えます。
ここでは簡単なプログラムの実装例をあげて説明しましょう0~9の手書きの数字画像をサポートベクターマシン(SVM)に読み込ませ、正解を学習するプログラムを作成します。
手書きの数字はMNISTと呼ばれる、データセットが機械学習用の性能評価用に提供されているのでそれを利用しましょう。
from keras datasets import mnist
from sklearn import svm,metrice
from sklearn.metrics import accuracy_score#MNISTデータをロードし、訓練データとテストデータを各々1次元データに変換する
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 784)
x_test = x_test.reshape(-1, 784)#LinearSVCで訓練データを学習する
clf = svm.LinearSVC()
clf.fit(x_train, y_train)
#学習結果に基づいてテストデータを検証し、正答率を表示
y_pred = clf.predict(x_test)
print(accuracy_score(y_test, y_pred))
上記のプログラムを実行すると、0.8662と学習結果が表示されるでしょう。つまりサポートベクターマシン(SVM)が学習した結果、手書き文字を86%の精度で認識できました。
このように、もしPythonでサポートベクターマシン(SVM)を実装したい場合は分類したいデータを用意するだけで簡単に利用できます。
サポートベクターマシンを実装するときの注意点

サポートベクターマシン(SVM)は、線形分離するように学習を行う手法ですが、データにはちょうど直線で分割できないものがあります。そのようなデータがあるときは、サポートベクターマシン(SVM)は正しく学習できません。
人間でも、判断に迷うことはありますよね。サポートベクターマシン(SVM)もうまく線形分離できないときがあります。このような問題に対して、下の2つの手法を用いて、サポートベクターマシン(SVM)に学習できるようにできます。
ソフトマージンとは、うまく直線で分離することをあきらめ、なるべく多くのデータを直線で分離しようとする手法のことです。これに対して、必ず直線で分離しようとする手法をハードマージンと呼びます。
カーネル化とは、直線で分離できないデータを曲線で分離する手法です。データを分離できそうな曲線を過程して、データの分類を行う手法です。
※詳しくはこちらで解説しています


さて今回は、サポートベクターマシン(SVM)を通して、学習がどのように行われていくのかについて解説しました。
サポートベクターマシン(SVM)の特徴は、画像認識などの分類や回帰問題を高速解くことができる手法です。サポートベクトルと呼ばれる特徴を使うことにより、他の機械学習アルゴリズムよりも少ない計算量で学習できます。近年のAI(人工知能)の分野では、サポートベクターマシンと深層学習を組み合わせることで大きな力を発揮するでしょう。
サポートベクターマシン(SVM)をPythonで実装する際には、sklearnという機械学習ライブラリを利用すると便利です。なぜならsklearnなら難しい数式をプログラミングしなくても、簡単に利用できるから。実装するうえでの注意点は、サポートベクターマシン(SVM)は、データを直線で分割することで学習できる手法ですが、現実のデータは直線で分割できない場合も多々あります。その場合は、サポートベクターマシン(SVM)以外の手法を利用する必要があります。
今回解説した手法は、機械学習の基本的なアルゴリズムですが、今後機械学習を使ううえで欠かせないものです。ぜひ今回の解説記事を読んで、実際に活用しましょう。
