
近年のAI(人工知能)の台頭により、さまざまな機械学習が注目されるようになりましたよね。その一つにSVM(サポートベクターマシーン)があります。
SVM(サポートベクターマシーン)とは、教師あり学習の2クラス分類で活用される強力なアルゴリズムで、AI(人工知能)のディープラーニング(深層学習)以前にずい分人気を博しました。多くの技術や研究において何らかの要素を分類するタスクは非常に頻繁に用いられます。よって、2クラス分類の線形識別器であるSVMは、さまざまな技術開発やデータ分析で活用されてきました。
この記事を読めば、SVM(サポートベクターマシーン)について短時間で簡単に理解できるので、データ分析や分類予測に役立つに違いありません。
そこで今回は、SVM(サポートベクターマシン)とは何かについてわかりやすくお伝えします。
SVM(サポートベクターマシン)とは

SVM(サポートベクターマシン)とは、2クラス分類の線形識別(直線で区分けできること)関数を構築する機械学習モデルの一種です。教師あり学習の分類と回帰で活用可能ですが、おもに分類のタスクにおいて強力な効力を発揮します。
分類は、さまざまなソフトやアプリ、マシーンの開発でなくてはならない要素ですが、これが高い精度で実現できれば、優れたビジネスモデルが構築できます。SVM(サポートベクターマシン)は、データの次元が大きくなっても識別精度を高く維持できるので、高い汎用性がある点が特長です。
SVMの仕組み

SVM(サポートベクターマシン)とは、ある集合体を2つのクラス群に分類し、未知のデータがそのどちらに属するかを判別するアルゴリズムです。その肝となるのが「マージン最大化」と「カーネルトリック」です。まず「マージン最大化」から説明しましょう。
ジャガイモの集荷を例にとって考えます。縦横で長い方のサイズが6cm以上で100g以上ならそのまま出荷、同6cm未満で100g未満なら加工品として使用というルールで識別するとします。
この場合、ジャガイモのクラス分けは、縦軸の指標を重さ、横軸の指標をサイズとした2次元の座標で表せます。(下図参照)
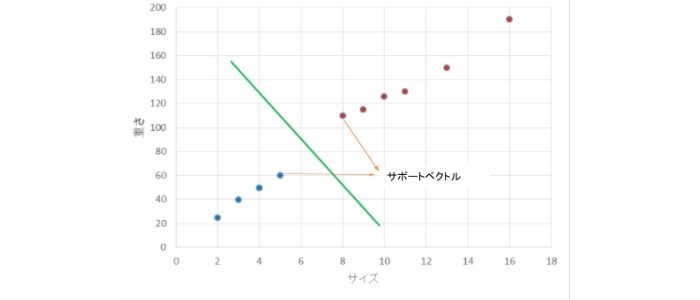
青の点群が、加工品用のジャガイモ、赤の点群が出荷用のジャガイモになります。そして、両クラスのジャガイモのうちでもっとも各クラスに近い2つのジャガイモを「サポートベクトル」と呼び、これがSVM(サポートベクターマシン)の語源です。
つまり、両クラスのうちで、それぞれの特徴にもっとも似通ったサポートベクトル同士からもっとも遠い位置に境界線を引けば、未知のデータについてもそのジャガイモを加工品にするか出荷するかを迅速に判別しやすくなります。
続いて「カーネルトリック」の説明に移りましょう。上記のジャガイモの例では、わかりやすく2次元の平面上に直線の境界線でクラス分類ができました。しかし、実際のビジネスや研究の現場での分類作業は、必ずしもこの例のように単純ではありません。
あるクラスは団子のように1か所にかたまり、もう一方のクラスがそれをドーナツ状にぐるりと取り囲むとすると、直線で境界線を引くのは無理ですよね。その場合、境界線は曲線となりますが、直線で区分できるデータを線形データと呼ぶのに対し、そうでないデータを非線形データといいます。
SVM(サポートベクターマシン)とは、2分類の線形識別関数ですが、この「線形」には、線形も非線形も含まれます。しかし、非線形データの場合、2次元の平面で分類するのが難しいため、よりわかりやすく分類する手法が「カーネルトリック」になります。
2次元ではわかりやすく区分できなくても、それを3次元、4次元・・・n次元と次元を増やしていけば、境界が線(2次元)だったのが、面(3次元)となり、さらに超平面(n次元)という形で、よりはっきりと分類されるようになります。これがカーネル法の考え方で、2次元のところを3次元、4次元・・・n次元とトリックのようにデータを変換することを「カーネルトリック」といいます。
このように、SVM(サポートベクターマシン)とは「マージン最大化」と「カーネルトリック」によって強力に2クラス分類する機械学習モデルです。
SVMを使うことのメリット・デメリット

SVM(サポートベクターマシン)とは何かがわかったところで、続いては、SVMのメリットとデメリットについて説明しましょう。
SVMのメリットは
- データの次元が大きくなっても識別精度が高い
- 過学習のリスクが低い
以上の2点です。一つずつ具体的に見ていきましょう。
データの次元が大きくなっても識別精度が高い
非線形データの場合は、カーネル関数を使ってデータ変換を行います。すると低次元では識別が困難だったデータ群が、高次元にデータ変換することで高い精度で識別できるようになります。カーネルトリックを使うことでSVMの識別精度は飛躍的に高まり、その知名度が大きく上がりました。つまり、データの次元が大きくなっても識別精度が高い、という点こそ、SVMの大きなメリットといえます。
過学習のリスクが低い
SVMは、分類を目的とした機械学習の中でも、100%完璧にすべてのデータを分類できなくても良いというソフトマージンの手法をとることが多いです。というのも学習データをあまりに厳密に分類しすぎると、そのアルゴリズムでは特定のデータしか正確に分類できず、未知のデータの分類を誤ってしまう過学習におちいる可能性があります。SVMはこの過学習のリスクが低く、誤検知しにくい点も大きなメリットです。
一方、SVMのデメリットは、
- 大規模なデータセットには不向き
- スケーリングが必要
以上の2点です。一つずつ見ていきましょう。
大規模なデータセットには不向き
実際の現場で、SVMで線形データのように単純な形で分類できるケースは限定的です。それよりも複雑な問題を解決するために特徴量を増やす必要があるケースの方が多く、学習データが大きくなるとSVMの計算量は指数関数的に増加します。よって、SVMではあまりに大規模なデータセットには不向きで、どちらかというと中小規模のデータセットに限って有効です。
スケーリングが必要
SVMとは、特徴量のスケールの影響を強く受けやすいアルゴリズムのため、データをそのまま使うと上手く分類できないことがあります。よって、データのスケーリングを細やかに行う必要があって手間がかかる点もデメリットといえます。
SVMを応用するとできること

SVM(サポートベクターマシーン)は、2分類の線形識別器を構築するのが目的のため、二者択一の予測に応用できます。例えば、翌日の株価が上がるのか下がるのか、の予測です。ある企業の過去の株価の変動データを学習して、前日よりも株価が上昇する場合と下落する場合をパターン認識すると、つぎの日の株価の動きを予測する機械学習モデルを構築できます。同じ考え方で為替の変動予想や立地条件や築年数データから未知の不動産が、ある価格より上か下かといった予測にも使えます。
あるいは、大雨による土砂崩れリスクの予測といったケースにも活用できます。斜面の傾斜角度や地質、さらに降水量や降雨時間などから土砂崩れを起こしやすいパターンを見いだせば、ピンポイントで場所を特定のうえ降雨予報データから、土砂崩れの危険性の有無について判定できます。
SVMを学ぶ上でのポイント

SVMを学ぶうえで押さえておくべきポイントは、(SVMを)いかなる分類予測にどのように活用するのか、です。SVMは、あまりに大規模なデータセットには不向きなアルゴリズムです。しかし、中規模であれば、十分活用できるでしょう。
その場合、比較的特徴量が多くなって問題が複雑化すればカーネルトリックを使います。ただ、データの特徴量が十分に多ければ、わざわざカーネルトリックを使わなくて済むケースもあるでしょう。その見極めを誤ってカーネルトリックを使ってデータ変換すると、あまりにも厳密に学習データに従いすぎるために過学習におちいる可能性が出てきます。すると予測精度が低下するため危険です。
このあたりの塩梅は、経験がものをいうので、SVMは、データさえそろえて学習させれば、最初から確実な分類ができるもの、と過信しすぎないようにしましょう。それよりも、習うより慣れよ、で根気よくさまざまなケースでトライ&エラーを繰り返し、肌感覚で習得する心構えが必要です。

さて今回は、SVM(サポートベクターマシン)とは何かについてわかりやすくお伝えしました。
SVM(サポートベクターマシン)とは、2クラス分類の線形識別器で、機械学習モデルの一種です。教師あり学習の分類と回帰で活用できますが、おもに分類のタスクにおいて強力な効力を発揮します。
また、SVM(サポートベクターマシン)とは、ある集合体を2つのクラス群に分類し、未知のデータがそのどちらに属するかを判別するアルゴリズムで、「マージン最大化」と「カーネルトリック」が肝となります。
2つのクラスを分ける境界線までの距離をマージンといい、とくに2つのサポートベクトルからもっとも遠い位置に境界線を設定するのが「マージン最大化」です。つまり、SVMとは、マージン最大を行うアルゴリズムといって良いでしょう。さらに、直線で区分できない非線形データの場合には、カーネルトリックを使って、故意にデータ変換を行い、より鮮明な分類を実現します。
SVMのメリットは、「データの次元が大きくなっても識別精度が高い」「過学習のリスクが低い」という点、一方、デメリットは「大規模なデータセットには不向き」「スケーリングが必要」といった点があげられます。
SVM(サポートベクターマシーン)とは、2分類の線形識別器を構築するのが目的の機械学習モデルのため、株価や為替の動き、不動産価格、災害リスクの予測などが可能です。ただし、SVMの活用にあたっては、データの規模やカーネルトリックの必要性を見極める必要があります。くわえて、SVMについて理解したからといって即マニュアル通りにうまく分類・予測ができるとは限らないので、根気よく経験を重ねましょう。
【お知らせ】
当メディア(AIZINE)を運営しているAI(人工知能)/DX(デジタルトランスフォーメーション)開発会社お多福ラボでは「福をふりまく」をミッションに、スピード、提案内容、価格、全てにおいて期待を上回り、徹底的な顧客志向で小規模から大規模ソリューションまで幅広く対応しています。
御社の悩みを強みに変える仕組みづくりのお手伝いを致しますので、ぜひご相談ください。

