
教師あり学習では与えられたデータとその正解データの組み合わせからある損失関数を最小化するように学習しますよね。本記事では機械学習で利用される様々な損失関数について紹介していきましょう。
そもそも損失関数とは
機械学習アルゴリズムは一般にどれだけ正しく予測できているかの指標として損失関数を利用し、その損失関数を最小化することで最も正しい予測ができているとします。
本章では著名ないくつかの損失関数とその性質の紹介をしていきましょう。
二乗誤差(Mean squared error)
まずは二乗誤差(Mean squared error)について解説していきましょう。
二乗誤差は回帰問題で広く利用される損失関数で、上記の数式で表されます。二乗誤差は予測値と正解ラベルの誤差を二乗したものですが、これはデータに含まれるノイズに平均0の正規分布を仮定した場合の最尤推定(さいゆうすいてい)の結果と一致します。
交差エントロピー誤差(Cross entropy error)
次に、交差エントロピーエントロピー誤差(Cross entropy error)について解説していきましょう。
交差エントロピー誤差は分類問題で広く利用される損失関数で、正解ラベル0か1と予測結果に自然対数をとったものの積で表現されます。正解ラベルに対応するものの損失関数の値が0でなくなり、また自然対数は入力が0の場合に負の無限大の値を返し、1の場合に0を返す関数です。
このことから交差エントロピー誤差は、予測の確信度が高い正解であればあるほど0に近い値を返し、確信度の低いものほど大きな値を返します。
平均絶対誤差(Mean absolute error)
続いて、平均絶対誤差(Mean absolute error)について解説していきましょう。
平均絶対誤差は主に回帰問題に利用される損失関数で、予測と正解の差を二乗しないため二乗誤差と比較して外れ値の影響を受けにくいという性質があります。また二乗誤差の場合は予測を大きく外したものに対してより大きなペナルティを与えるのに対し、平均絶対誤差では予測を大きく外したものも予測との差が小さいものも同じスケールでペナルティを与えます。
二乗対数誤差
最後は二乗対数誤差について紹介していきましょう。二乗対数誤差は二乗誤差における正解と予測値に自然対数を取ったものです。自然対数は1以上の入力に対して以下のような値をとります。
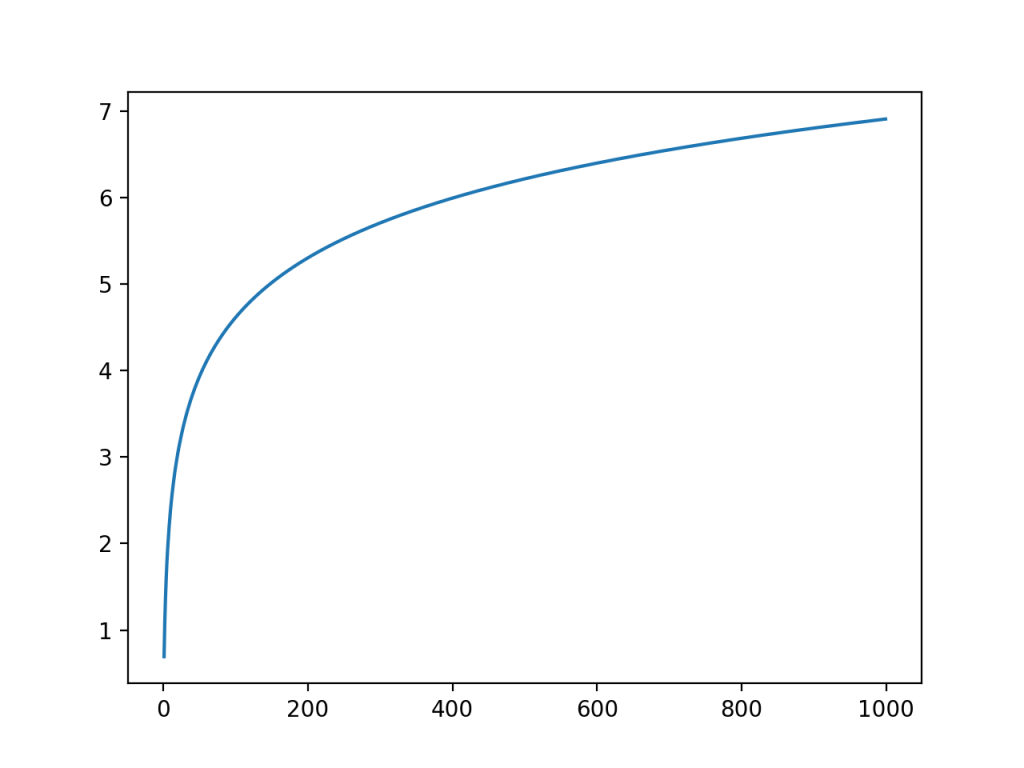
入力が大きくなるほど出力の増加具合が鈍化していることがわかります。この自然対数を取ることで、値が大きすぎる予測に対してのペナルティを相対的に小さくすることができるんですね。この性質によって、小さな値はより細かく予測できるように、大きな値は少し大雑把に予測するようにモデルを調整することができます。
例えばある商品の値段を予測したい場合に、100円の商品を1万100円と予測すると問題になりますが、10万円の商品を11万円と予測してもあまり大きな問題にはなりません。こういった問題を自然対数を取って大きな値を小さくスケーリングすることで解決することが可能になります。
このように損失関数は様々なタスクに対して複数ありますが、自身が応用したい問題が何であるかを深く理解し、それに適した損失関数を利用することでより良い機械学習モデルを構築することができます。
まとめ
損失関数について重要な点をまとめましょう。
- 教師あり学習における予測と正解の誤差を計算する関数で、損失関数を最小化することでモデルの学習を行う。
- 分類における交差エントロピー誤差、回帰における二乗誤差は最も広く利用される誤差関数。
- 解くべき問題に即した損失関数を選択することで、実運用でのメリットを生むことができる。


