
Kaggleといったデータ分析コンペに参加すると、LightGBM(ライト・ジービーエム)という名前を聞きますよね。LightGBMはコンペで良く使われる手法だとは知っているけど、どういう仕組みなのか、どうやって使えば良いか気になったことがある人もいるかもしれません。
LightGBMはマイクロソフトが2016年に開発した勾配ブースティングによる機械学習アルゴリズムの一つです。勾配ブースティングは、Kaggleの上位ランキングの半分以上が使用していると言われるほど、強力です。LightGBMは、勾配ブースティングの中でも性能が高いアルゴリズムになります。既にKaggle に参加しているKagglerの皆さんも、これからKaggleへの参加を考えている皆さんも、是非LightGBMを身につけて、コンペの上位ランクを目指しましょう!
そこで今回は、LightBGMの準備から実装までの使い方について徹底的に解説します。
LightGBMとは

LightGBMとは、決定木を用いた勾配ブースティングの手法です。まず初めに、LightGBMを理解するために、決定木と勾配ブースティングについて解説しましょう。
例えば図1はアヤメの分類を例にした決定木を表しています。ここでは、「花弁の長さ」、「花弁の幅」といった特徴量を持つデータから「セトサ種」、「バージカラー種」、「バージニカ種」といったアヤメの種類を分類します。決定木による学習を行うことで、「花弁の長さ」が2.5cm未満の場合は「セトサ種」、「花弁の長さ」が2.5cm以上で「花弁の幅」が1.8cm未満の場合は「バージカラー種」、「花弁の長さ」が2.5cm以上で「花弁の幅」が1.8cm以上の場合は「バージニカ種」と分類を行うことができます。
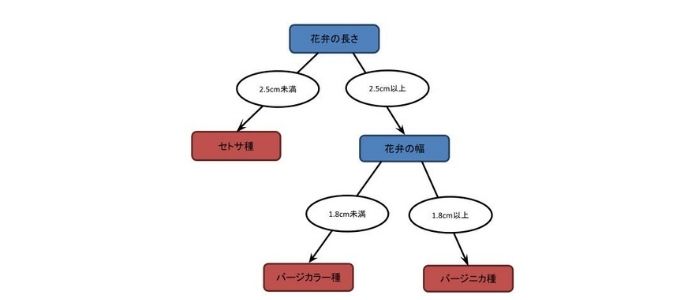
図1 アヤメの分類の決定木
続いて、勾配ブースティングについて紹介しましょう。勾配ブースティングとはアンサンブル学習の一つであるブースティングの手法です。アンサンブル学習は複数の機械学習モデル(弱学習器)を組み合わせて一つの学習モデル(強学習器)を生成します。ブースティングは弱学習器を直列につないで順番に学習しますが、特に勾配ブースティングでは前の弱学習器の予測値の誤差を次の弱学習器が引き継いで学習すれば、効率よく学習を行えます。LightGBMは、勾配ブースティングの弱学習器の学習に決定木を用いたものになります。
LightGBMの計算原理

続いて、LightGBMの計算原理について紹介しましょう。LightGBMは決定木の学習を行う際に、Leaf-wiseと呼ばれる方法で木構造を生成していきます。Leaf は木構造の葉のことで、末端の要素を意味しています。Leaf-wiseでは、葉を成長させる方向の的を絞って木を生成します。図2はLeaf-wiseによる木構造の成長の例です。ある特定の方向に葉が成長していることがわかりますよね。LightGBMはLeaf-wiseを用いて木構造の成長の的を絞ることで、学習時間が短くなるという利点があります。
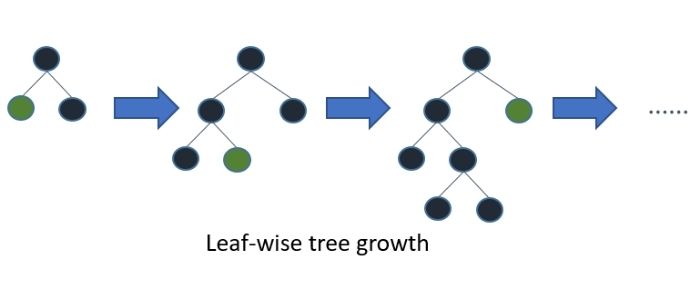
図2 LightGBMの決定木の学習
(引用:https://lightgbm.readthedocs.io/en/latest/Features.html)
木構造が成長する方向、つまり成長の分岐点を探索するのにはhistogram-basedアルゴリズムと呼ばれる手法を使用しています。histogram-basedアルゴリズムでは、特徴量をヒストグラムで離散化すると、計算量を抑えられます。これにより、LightGBMは大規模なデータセットであっても比較的短時間で学習ができるという利点があります。
LightGBMとXGBoost,CatBoostとの違い

決定木を用いた勾配ブースティングには、LightGBM以外にXGBoostやCatBoostと呼ばれる手法があります。XGBoostは2016年に発表された手法で、精度が高いという特長があります。一方で、LightGBMと異なり、木構造は指定した深さまで成長させるアルゴリズムを採用しています。これにより、計算量が多く、学習に時間がかかるという問題がありました。この問題に対処するためにLightGBMが開発されました。
CatBoostは2017年にYandex社により発表された手法です。XGBoostと同様に木構造は指定した深さまで成長させるアルゴリズムを採用していますが、木構造を最適化して精度の向上や計算量を削減しています。また、XGBoostやLightGBMと異なり、数値に加えて文字列などのカテゴリ変数を容易に扱えるという特長もあります。
LightGBMのインストール

次に、LightGBMのインストール方法を紹介します。LightGBMはPythonによるライブラリが提供されています。LightGBMをインストールする前にPythonのインストールをしておきましょう。Pythonは公式サイトからPCのOSにあったインストーラーをダウンロードしましょう。
続いて、LightGBMはPythonのパッケージをインストールするユーティリティであるpipコマンドを使ってインストールをします。インストールはOSのコマンドライン・シェルから以下を実行するだけです。
Windowsの場合であれば、コマンドプロンプトからこのコマンドを実行しましょう。OSのコマンドライン・シェルからPythonのインタプリタを起動してして、以下コマンドが実行できればインストールは成功しています。
LightGBMの実装方法

続いて、実際にPythonを使って、LightGBMの実装方法を見てみましょう。
LightGBMは先ほどインストールしたライブラリを使用します。また、実装にはscikit-learn(サイキットラーン)と呼ばれる機械学習のオープンソースライブラリも使用します。今回は、アヤメの分類のデータセットを使用して、LightGBMを試してみましょう。
>>> from sklearn import datasets
>>> from sklearn.model_selection import train_test_split
>>> dataset = datasets.load_iris()
>>> x, y = dataset.data, dataset.target
>>> train_x, test_x, train_y, test_y = train_test_split(x, y,stratify=y,shuffle=True,random_state=42)
>>> train_data = lightgbm.Dataset(train_x, train_y, feature_name=list(dataset.feature_names))
>>> test_data = lightgbm.Dataset(test_x, test_y, reference=train_data)
>>> param = {‘objective’: ‘multiclass’,’metric’: ‘softmax’,’num_class’: 3,’verbose’: -1,’seed’: 42,’deterministic’: True,}
>>> model = lightgbm.train(params=param,train_set=train_data,valid_sets=[train_data, test_data],num_boost_round=100,early_stopping_rounds=50,verbose_eval=10,)
>>> pred = model.predict(data=[test_x[0]],num_iteration=2)
>>> print(‘pred’)
まず、scikit-learnを使用してアヤメの分類のデータセットをロードし、学習データの特徴ベクトルtrain_xと学習データのクラス分類train_yを用意します。同様にテストデータの特徴ベクトルtest_xとテストデータのクラス分類test_yも準備します。
続いて学習データとテストデータをLightGBMのライブラリへ入力可能な形式であるtrain_dataとtest_dataに変換します。そして、train_data を用いてLightGBMの分類器の学習を行います。最後に学習した分類器にtest_dataを入力し、予測を行います。
LightGBMを使うときの注意点

ここまでLightGBMの実装方法を見てきましたが、注意点もあります。それはLightGBMの性能のチューニングです。
一般的に機械学習モデルの性能を向上させるために、ハイパーパラメータのチューニングがよく行われます。LightGBMでは多くのハイパーパラメータの設定が可能となっています。例えば、ブースティングの繰り返し数を指定するnum_iterations、学習率を指定するlearning_rate、木の最大の深さを指定するmax_depth、イテレーションの強制終了を指定するearly_stopping_roundなどがあります。ハイパーパラメータのチューニングはグリッドサーチといったようなハイパーパラメータの組み合わせを変えて調査する手法があります。
一方で、LightGBMのようなブースティングの精度は、一般的にハイパーパラメータのチューニングに比べて、特徴量の選択の方が影響が大きいと言われています。LightGBMのハイパーパラメータをチューニングする前に、適切な特徴量が選択されているかチェックを行いましょう。

さて、今回はLightBGMの準備から実装までについて解説しました。LightGBMについてお伝えした内容は以下です。
- LightGBMは決定木を用いた勾配ブースティングの手法
- LightGBMは決定木の学習を行う際に、Leaf-wiseと呼ばれる方法で木構造を生成する
- 決定木を用いた勾配ブースティングには、LightGBM以外にXGBoostやCatBoostと呼ばれる手法がある
- LightGBMはPythonによるライブラリが提供されている
- LightGBMのハイパーパラメータをチューニングする前に、適切な特徴量が選択されているかチェックが必要
決定木を用いた勾配ブースティングの手法であるLightGBMは、 Kaggleといったデータ分析コンペでも使用されおり、非常に強力な機械学習アルゴリズムです。LightGBMは今後もデータ分析の分野でよく使われていくでしょう。是非理解をして身につけましょう。
【お知らせ】
当メディア(AIZINE)を運営しているAI(人工知能)/DX(デジタルトランスフォーメーション)開発会社お多福ラボでは「福をふりまく」をミッションに、スピード、提案内容、価格、全てにおいて期待を上回り、徹底的な顧客志向で小規模から大規模ソリューションまで幅広く対応しています。
御社の悩みを強みに変える仕組みづくりのお手伝いを致しますので、ぜひご相談ください。

