
自然言語処理をしているとよく出てくる潜在的ディリクレ配分(LDA:Latent Dirichlet Allocation)。LDAの名前は知っているけれど、どんな時に使うのか、どんな仕組みなのか気になった経験がある人もいますよね。
LDAはトピックモデルの一つで、文書分類や類似文書の検索などを行うことができます。トピックモデルは古典的な自然言語処理のモデルで、統計的な手法をベースとしています。LDAと聞くと、実装が難しそうな印象もありますが、機械学習用のライブラリがサポートされているので、簡単に試せます。
そこで今回は、LDAの仕組みや使い方など基本的なことをできるだけわかりやすく紹介します。この記事でLDAを理解して、自然言語処理に活用しましょう。
LDAとトピックモデルの関係

まず初めに、LDAとトピックモデルの関係について紹介しましょう。
トピックモデルとは文書などのデータに隠れた潜在的なトピックを確率的に推定するモデルのことです。ここでのトピックは話題や分野、カテゴリーといったものを意味しています。
トピックモデルには、LSI(Latent Semantic Indexing)、PLSI(Probabilistic LSI)などがありますが、LDAもその一つになります。LSIは情報検索の分野から生まれたもので、同義語を検索することを目的に考えられました。PLSIはLSIを確率的なモデルとして考え直したものになります。その中でLDAはPLSIを更に発展させたモデルで、もっともよく使われています。LDAを理解して、是非使いこなせるようになりましょう。
潜在的ディリクレ配分LDAってどんなモデル

それでは、LDAがどんなモデルか説明していきましょう。LDAは2001年にDavid M. Blei、Andrew Y. Ng、Michael I. Jordanによって提案されたもので、文書が生成される過程を確率的にモデル化したものです。
こちらの図はLDAをグラフィカルモデルで表した図です。グラフィカルモデルとは、確率分布をグラフで表現したもので、矢印は確率変数間の依存関係を意味しています。
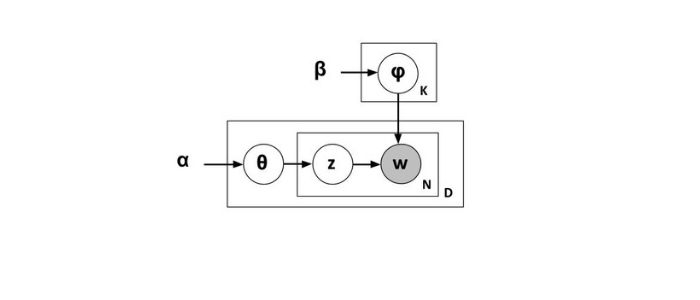
φは各トピックにどの単語が出現するかを表す多項分布です。多項分布は二項分布を一般化したもので、確率分布の一種です。Kはトピックの数を意味しており、四角い箱は繰り返し実行することを意味しています。wは文書に含まれる単語で、実際に観測された既知のデータです。
θは各文書がどのトピックに属するかを表す多項分布です。z は単語w に割り当てられたトピックを表しています。ここでNは単語の数、Dは文書の数を意味しています。
また、αとβは多項分布のパラメータを得るためのディリクレ分布のパラメータになります。ディリクレ分布は連続型の確率分布の一種です。
LDAは既知のデータであるwをもとに未知のパラメータを推定します。これにより、文書がどのトピックに属しているか推定できます。パラメータの推定はベイズ推定と呼ばれるもので、データのサンプリングが難しい確率分布を近似して求めるための手法であるギブスサンプリングを用います。
LDAは何ができるのか

続いて、LDAはどういったことができるのか見ていきましょう。LDAがもっともよく使用されるのは文書分類です。例えば、いろいろな種類のニュース記事が複数あったときに、ニュース記事のカテゴリーを推定して分類するといったようなことができます。
また、時系列データを扱えるようにLDAを拡張したDTM(Dynamic Topic Model)というモデルがあります。このモデルが使えるのは、トピックの流行。具体的には過去に発売された10年分の小説をDTMで学習すると、恋愛、SFといった小説のジャンルの流行り廃りを時系列に調べることができます。
LDAの特徴とは

次に、LDAの特徴である潜在的なトピックとはどういったものか見ていきましょう。ここで説明を簡単にするため、LDAに入力する全ての文書は「play」、「piano」、「baseball」の3単語だけで書かれていることとしましょう。
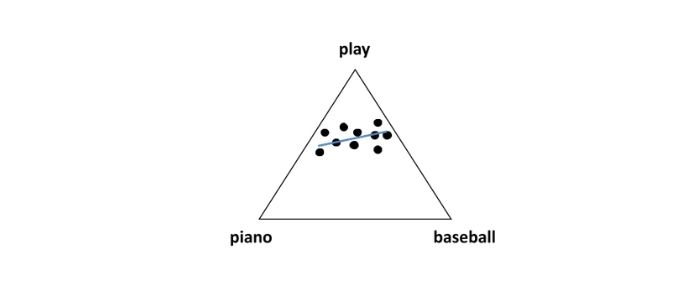
こちらの図は、は3単語を座標とした文書の分布を示しています。「play」と「piano」、「play」と「baseball」は同じ文書に出現することが多いことがわかります。一方、「piano」と「baseball」は同じ文書内に出現することは非常に少ないです。
このように、LDAは文書内に出現する単語の偏りによって、潜在的なトピックの分布を得ることができます。図の青い線は文書のトピック分布を意味し、トピックは単語の出現確率分布で表現されます。
PythonでのLDAの使い方

最後に、実際にPythonを使って、LDAを使ってみましょう。LDAにはgensim(ジェンシム)と呼ばれる機械学習のオープンソースライブラリを使用します。
>>> from gensim.corpora.dictionary import Dictionary
>>> from gensim.models.ldamodel import LdaModel
>>> dictionary = Dictionary(common_texts)
>>> corpus = [dictionary.doc2bow(x) for x in common_texts] >>> lda = LdaModel(corpus, num_topics=5)
>>> test_docs = [[‘time’, ‘computer’, ‘system’, ‘human’]] >>> test_corpus = [dictionary.doc2bow(x) for x in test_docs] >>> vector = lda[test_corpus[0]] >>> print(vector)
[(0, 0.042683676), (1, 0.34145382), (2, 0.040936615), (3, 0.04001059), (4, 0.5349153)]
まず、LDAモデルを生成するためにgensimが用意しているテスト用のデータセットcommon_textsを用意しましょう。続いて、gensimのdoc2bowを使用して、単語ごとの頻度を表す特徴ベクトルcorpusを得ます。最後にcorpusをgensimが用意しているLdaModelに与えることでLDAモデルを生成することができます。LdaModelには分類するトピックの数num_topicsを与えます。ここで、num_topicsは5としています。
LDAモデルにテスト用の文書test_docsを入力してみましょう。test_docsもdoc2bowを使用して特徴ベクトルtest_corpusに変換した後、生成したLDAモデルldaに与えます。そうすると入力した文書のトピックごとの確率が出力されます。ここでは、IDが4のトピックが最も高い確率となっています。

さて、今回はLDAについてご紹介しました。LDAについてお伝えした内容は以下です。
- トピックモデルは潜在的なトピックを確率的に推定するモデルのこと
- LDAは文書が生成される過程を確率的にモデル化したもの
- LDAは文書分類やレコメンドシステムに応用できる
- LDAは文書内に出現する単語の偏りによって、潜在的なトピックの分布を得ることができる
- LDAはgensimを使用することで簡単に試すことができる
近年、ディープラーニングの進化により、自然言語処理の分野でもディープラーニングが多く使われるようになってきました。しかしながら、LDAは古典的な機械学習の手法ではありますが、まだまだ活用されています。是非LDAを理解して身につけましょう。
【お知らせ】
当メディア(AIZINE)を運営しているAI(人工知能)/DX(デジタルトランスフォーメーション)開発会社お多福ラボでは「福をふりまく」をミッションに、スピード、提案内容、価格、全てにおいて期待を上回り、徹底的な顧客志向で小規模から大規模ソリューションまで幅広く対応しています。
御社の悩みを強みに変える仕組みづくりのお手伝いを致しますので、ぜひご相談ください。

