現在世間を賑わしているAI技術と言えばDeep Learningですよね。Deep Learningで画像を生成できるという事は度々ニュース等で取り上げられることもあり、実際に目にされた事がある方もいらっしゃることでしょう。
こうしたニュースが出てくるようになった背景には、2014年に発表されたGenerative Adversarial Network(GAN)というアイデアが深く関係しており、様々な研究の成果もあってこの技術は最初に発表されてからたった5年で凄まじい進化を遂げています。
例えば、 This Person Does Not Exist というサイトにアクセスすると人物の画像が表示されますが、これが現実には存在しない人だと聞いて驚かれる方は多いかもしれません。
このサイトに表示される人物画像は全てDeep Learningによるもので、人物画像をお手本に学習させ、お手本と見分けがつかない偽物の画像を生成するよう学習させたモデルであるGenerative Adversarial Network(GAN)が採用されています。
今回は、そうした凄まじい進化を遂げている技術、Generative Adversarial Network(GAN)の進化を紹介していきます。
Generative Adversarial Network(GAN)はここから始まった!
2014年 – Generative Adversarial Nets [2]

2014年に初めてGenerative Adversarial Network(GAN)というDNNモデルの論文[2] が発表されました。これが初めてGANのアイデアが発表された論文となります。この仕組みを紹介します。
Generative Adversarial Network(GAN)の仕組み
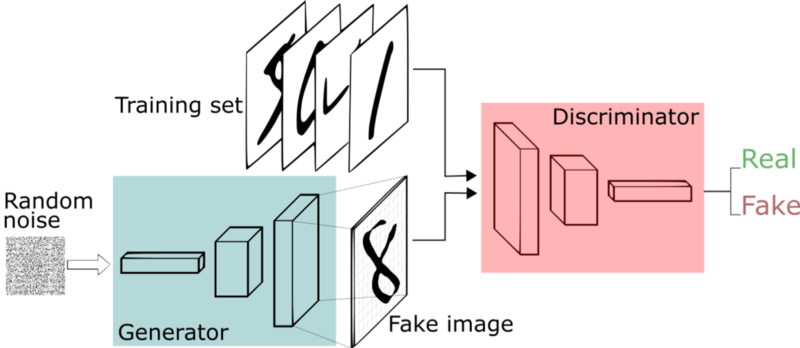
Generative Adversarial Network(GAN)は 1つのネットワークではなく、 「Generator」、「Discriminator」 と呼ばれる2つのネットワークを使うという特徴があります。
Generatorは画像生成のを担当します。 Discriminatorは、入力された画像が本物なのか、またはGeneratorが生成した偽物なのか判定を担当します。このネットワークを学習する際は、GeneratorはDiscriminatorを騙せる画像を生成しようとし、Discriminatorはより本物と偽物を正確に判別できるよう同時に学習させていきます。
この2つのモデルを敵対的(Adversarial)に学習させるというのが、DNNで画像の生成を可能とした革新的なアイデアでした。Facebook AI Rearch の Yann LeCunも、機械学習にて、ここ10年で最も面白いアイデアと発言しています。
https://github.com/eriklindernoren/PyTorch-GAN に公開されているGANの実装を実行し、手書き数字の画像生成の学習途中結果を表示させたものがこちらです。

学習初期は無意味な画像が生成されていますが、GeneratorとDiscriminatorの学習が進むにつれ、本物の画像に近い画像が生成されていくのが確認できるかと思います。
以上が簡単な仕組みの紹介となります。
この仕組みで生成出来る画像は非常に限定的で、生成できる画像のサイズは28×28程度の非常に小さいサイズの画像しか生成できません。また、生成結果の(c) , (d) で確認できるように、お手本画像によってはまともな画像が生成できなかったりします。その上、非常に学習が難しく、お手本にする画像と学習のパラメータによっては全く学習が進まなくなったり、同じ画像しか生成しなくなってしまう、といった事がよく起こりました。
この仕組みでだけでは、はじめに紹介した https://thispersondoesnotexist.com/ のサイトで表示されているような綺麗な画像は生成できません。ただ、今までできなかった画像の生成が可能となったというインパクトは大きく、これ以降、様々な研究が行われるようになりました。
2016年に高精度な画像生成と生成される画像のコントロールが可能に
2016 – DCGAN[3]

2014年にGANが発表されてから、GANにCNNを使うという試みは行われていましたが、目立った成果は出ていませんでした。 しかし2016年に Generatorにtransposed convolution(Deconvolutionと呼ばれることもあります)を使い非常に高精度な画像を生成できた研究結果が公開されました。
上記はベットルームの画像をお手本に生成された画像で、全て実際には存在しないベッドルームです。 2014年のオリジナルに比べ、非常に綺麗な画像が生成可能となっており、また生成される画像サイズも 64×64 と高解像度の画像が生成可能となりました。
ランダムな画像を生成するだけではなく生成される画像をコントロールする方法もこの論文で検証されています。
DCGANの仕組み
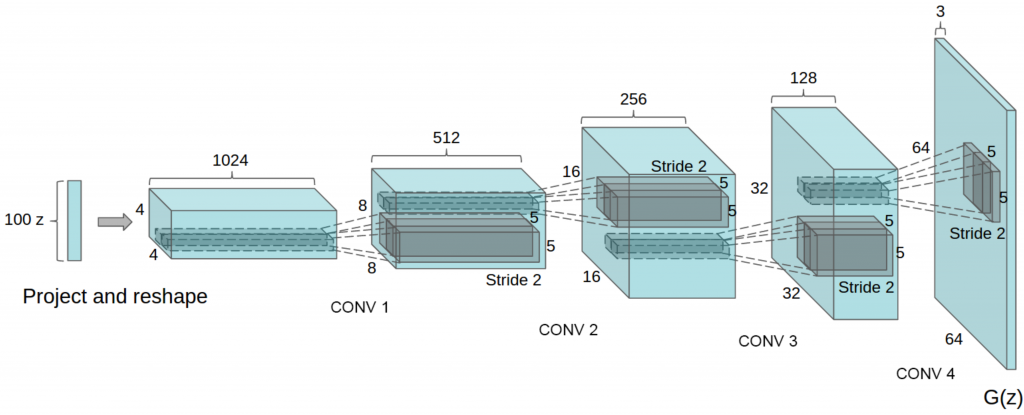
DCGANで提案されたGeneratorは、上記のような構造をしています。画像の生成元として、100個のランダムな数値を入力として利用し、 そのデータを 4x4x1024 のデータに射影します。その射影したデータを transposed convolution という計算を行い, 8x8x512 -> 16x16x256 ・・・と段階的にアップサンプリングを行い、最終的に 64x64x3 つまり 画像サイズが64×64 RGBカラー画像を生成しています。
DCGANでは、 transposed convolution を使い画像のアップサンプリングができるということを実証した点が画期的でした。
学習コストは高いが本物と瓜二つの画像生成を実現
2017 – Progressive GAN[4]
2017年にProgressive GANとい名前のGANが発表されました。最大で1024×1024という高解像度の画像が生成可能で、生成される画像の品質も高品質となりほぼ本物と見分けがつかなくなりました。
Progressive GANの仕組み
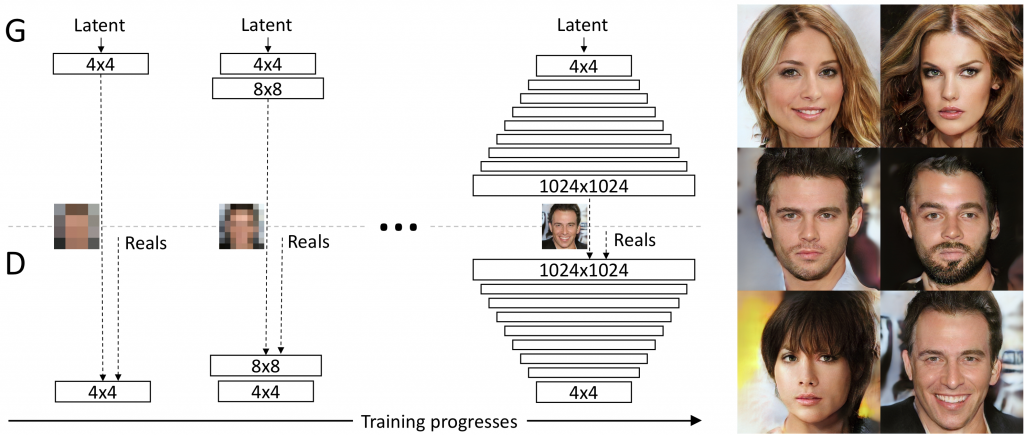
Progressive GANでは、GeneratorとDiscriminatorを段階的に学習させ積み上げて行くような方法を使います。
まず、4×4の画像生成するGeneratorとそれを判別するDiscliminatorを学習させます。この学習が完了したら、GeneratorとDiscliminatorに層を追加し、8×8画像が扱えるようにして学習を行います。これを繰り返して1024×1024の画像を生成できるネットワークが学習できるようになりました。
このように、段階的に層を増やして学習させていくという手法は Progressive Neural Networks[5] で発表された研究を元に考案されています。
この手法で、かなりの高品質の画像が生成できるようになりましたが、4×4 , 8×8 と段階的に学習させるため、お手本用の画像もそれぞのれのサイズを用意せねばならず、データの準備にかなりの手間ががかかかります。また、学習自体にもかなりの時間が必要となり、動画で学習完了に約2日、となっていますがこれはGPUを8台同時稼働させた場合の時間で、通常のPCのようにGPUが1台のみの環境では、学習結果が出るまで約2週間かかります。
こちらに実際に動かせるコードが公開されていますので、興味のある方は実行してみてはいかかでしょうか。
https://github.com/tkarras/progressive_growing_of_gans
はじめに紹介したhttps://thispersondoesnotexist.com/ は、このProgressive GANを改良したSytleGan[6] で生成されています。
空間的な課題をクリアし生成可能な画像が大幅にアップ!
2018 Self-attention GAN (SAGAN)[7]

2016年にDCGANが発表されてから、CNNベースのGANがどんどん進化していきましたが、CNNゆえの弱点がありました。 CNNは仕組み上局所的な特徴のみを抽出するため、画像全体の特徴というものは捉えられません。
このため、犬画像を例とすると毛並みなどの模様はうまくGANで生成できますが、 犬の足などは全体の位置とも関わるため、うまく生成できませんでした。
上記の2017年の結果を見るとわかりやすいのですが、犬の目や耳、毛並みなど部分的に見ると綺麗なのですが、胴体が長すぎたり、顔が2つあったりと全体的には不自然な画像が生成されています。
このため人の顔は本物と見分けがつかない程の精度で生成できるものの、犬の全体写真などはうまく生成できないというように、実はGANで生成できる画像は限定的でした。 CNNでも層を深く重ねる事で全体の特徴を抽出する事は可能なのですが、そうした場合学習がかなり難しくなるため、GANで成功しているものはありませんでした。
Self-attention GAN(SAGAN)はこの問題を解決した初めてのGANで、空間的な特徴をもつ画像もかなり綺麗に生成可能となりました。つまり、GANで生成可能な画像の種別が大幅に増えた事になります。
まとめ
さて、今回はGenerative Adversarial Network(GAN)の進化について紹介してきました。
2014年にGenerative Adversarial Network(GAN)の原理が発表された際、すごく小さなモノクロ画像が生成できるというだけでしたが、 たった4年で本物と見分けがつかないレベルのカラー画像が生成できるという所まで進化しました。
また、今回はGANによる画像の生成のみを紹介しましたが、

のように、ある画像を別の画像に変換する事も可能です。このDeepNudeというアプリはリリース後に大変な物議を醸したことで有名なのでご存知の方も多いことでしょう。
この例のように、技術の進化に伴ってサービス開発者、使用者にも配慮が求められますが、今後も更なる進化が期待できる領域ですので、ぜひ注目していきたいですね。
<参考文献・サイト>
(1) Zhengwei Wang, et al. “Generative Adversarial Networks: A Survey and Taxonomy”,2019
(2) I. Goodfellow et al., “Generative Adversarial Nets”, 2014
(3) Alec Radford, et al. “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, 2016
(4) Tero Karras, et al. “Progressive Growing of GANs for Improved Quality, Stability, and Variation”, 2017
(5) Andrei A. Rusu, et al. “Progressive Neural Networks”, 2016
(6) Tero Karras, et al. “A Style-Based Generator Architecture for Generative Adversarial Networks”,2018
(7) Han Zhang, Ian Goodfellow, et al. “Self-Attention Generative Adversarial Networks”, 2018
(8) Yanghua Jin et al., “Towards the Automatic Anime Characters Creation with Generative Adversarial Networks”, 2017
(9) https://www.freecodecamp.org/news/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394/


コメントをどうぞ