
AI(人工知能)を学習させたはいいけれど「全然使えませんよこれ!」なんていう過学習に陥ってしまったら困りますよね。過学習とは、訓練データ(学習データ)に対してはきちんと正解できるけど未知のデータに対しては全然当たらないモデルの状態のことです。
※モデル:ある事象を簡略化して本質を表したもの(パターンやルールを数式で表現したもの)
※訓練データ:機械学習を用いてモデルを学習させていく際に使うデータ
先日過学習への対策をなんとか整理した僕はほっと一息ながら熱いコーヒーを片手に手元のAI(機械学習)の参考書をペラペラめくっていたんですが(澄ました顔で)、そこで思わずコーヒーを吹き出しそうになりました。
が、学習曲線!???
なんと、過学習の対策の一つ「学習曲線」とやらを僕は見落としていたことがわかったんです。過学習からテーマを変えて次に移ろうとしていた僕だったので、「こりゃあかん!」と人目をはばからず叫んで(心の中で)急遽計画を変更。焦りながら「学習曲線」について整理・理解し始めることに。。。
気づいた方もいらっしゃるかもしれませんが、今回は「◯◯曲線」がテーマになるので「曲線」の美しいバナナをイメージとして採用しました。今回の記事は少し長いので、バナナを頬張りながら気楽に読んで頂くのが良いかもしれません。
つまり今回の記事は、先日過学習の対策を整理した「AI(機械学習)でよくある問題過学習って?ゼロからわかる基本と対策」の続編とも言える内容です。
学習曲線を見れば汎化性能を高めるための今後の行動を検討できる
 学習曲線について早速調べてみたところ、学習曲線(learning curve)とは、
学習曲線について早速調べてみたところ、学習曲線(learning curve)とは、
訓練データの量に対する、モデルの汎化性能をプロットしたもの
というもので、訓練データによるモデルの性能と検証データによるモデルの性能が訓練データの量に応じてどう変化していくかを表したグラフだとのこと。次のようなイメージです。
※検証データ:モデルの性能を評価するために使うデータ
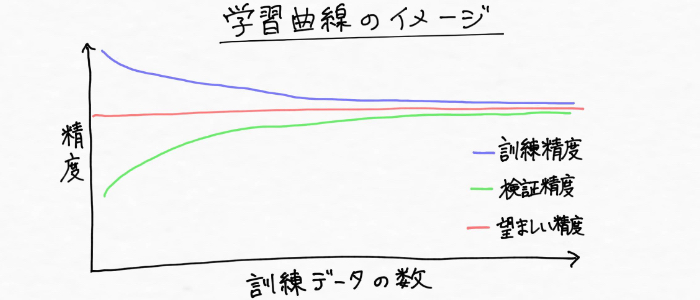
ふーん、こういうグラフなんだ・・・
ってことわかったんですけど、僕にはいまいちピンとこない 汗
だって、、確かに過学習の対策として「訓練データの量を増やす」っていうことが効果的っていうのは先日理解したけど、それわざわざグラフにして何の役に立つの?って思っちゃったから。。。
しかし!!そんな疑問は学習曲線についてさらに理解していくうちに解決されました(^^)
というのは、「訓練データの数を増やす」という行為は、汎化性能を高めるのに効果的だけれど、実際に訓練データを新たに収集することは時間や費用が非常に高くついたり、実現不可能であることがよくあるようなんです。
以前、最前線で機械学習をビジネスに活用している方が次のように話していました。
例えば、入社前テストと人事考課の情報を元に、「入社後の人物のパフォーマンスを予測する機械学習モデルを作って欲しい!」とお客様から依頼が来た場合、手元にあるデータを使って機械学習を回してみて「精度上がんないから訓練データもっと必要だ!」となったとします。
しかし、新たな入社前テスト結果と人事考課の情報を収集するには、来年の採用時期まで待たなければいけないのでデータ収集にはコストがかかってしまう。
こんな風に、「訓練データを増やすことで汎化性能を高められる!」っていうのは口で言うのは簡単ですけど、実際問題それが困難な場合が多々あるようで、データ収集をする前には「そもそも訓練データの数を増やして本当にコストに見合うだけの精度が上がんの?」という疑問に答えられないといけません。
「モデルが過学習に陥ってるからデータの数を増やしたらいい」っていう単純な考えだけでは、データ収集へ踏み切る根拠として弱すぎます。だからこそ、こうした問いに答えられる根拠や判断できるものが欲しい!
そんな要望に応えるのが「学習曲線」なのです(学習曲線めっちゃ重要じゃん!)。学習曲線を見ることでモデルの現状を把握し、訓練データの量の変化に伴うモデルの性能変化を検討できます。
例えば汎化性能が横ばいであれば、「訓練データを収集する行為にこれ以上コストを投入することはおそらく無駄でしょ」という判断ができます。そんな状態なら現状の性能を良しとして受け入れるか、あるいはモデルを改善するために別の方法を考えることへ頭が働きますよね!!
逆に、もし学習曲線を見て「汎化性能が継続的に改善されてる!!」という傾向が見られるなら、「訓練データを追加することが良い投資となるはず!」などの判断ができます。
なるほどなるほど、かなり理解が深まりました(僕の)
ちなみに、僕は新卒入社した会社で受けたSPI結果が異常に良かったらしく、裏では「すごい人材がきた!」とかなり注目を集めていたようですが、蓋を開けてみれば期待を裏切り続け「歩く負債」「2013年卒130万人中130万位の社員」とまで言われた始末(逆にすごい・・・)
AI(機械学習)は過去のデータから未来を予測しますが、時に過去のパターンに当てはまらない例外が起こるのが現実。SPIもAI(機械学習)も裏には統計学が深く関係しているけれど、僕の例のように予測が100%的中するなんてことは理論上ありえません。
学習曲線を用いることで訓練データの量に応じてモデルの性能がどのように変化していくかを知ることができ、今後の行動を決めるための検討材料として使える。
モデルの状況判断に役立つ学習曲線

次は学習曲線の見方について具体的に整理していきます!
調べていったところ、学習曲線を見ることで現状のモデルの状態を客観的に掴むことができ、過学習に陥っているのかまたは学習が全然足りなくて訓練データにさえ適合できていない学習不足(未学習、underfitting)なのか、そんな状況判断に学習曲線は役立てられることが分かりました!
また、統計やAI(機械学習)の分野では、
- 学習不足=「バイアスが高い(ハイバイアス)」
- 過学習=「バリアンスが高い(ハイバリアンス)」
という表現をするようで、ややこしいです 汗。
学習曲線についてもっと理解を深めるために、モデルのバイアスが高い(学習不足)状態とバリアンスが高い(過学習)状態とで分けて学習曲線を見ていきます!(^^)
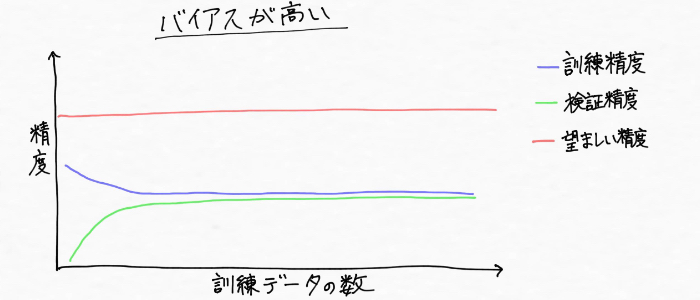
バイアスが高い状態(学習不足)への対策
モデルが学習不足(ハイバイアス)に陥っているイメージ
まず「バイアス」とは偏りを意味する言葉ですが、モデルのバイアスが高い、ハイバリアンスの状態(学習不足)とは、上図のように訓練データのパターンをうまく捉えるにはモデルの複雑さが不十分(柔軟性が低い)な状態です。(ガチガチにもほどがあるよ!!Σ(゚д゚lll))
また、訓練データとモデルの精度の関係性は、次のように訓練データと交差検証による正解率が両方とも低くなっている状態です。そして真の値に比べてモデルの予測値のズレも大きい 汗
皆さん懐かしの漢字の勉強に例えるならば、「漢字ドリルの問題は全然解けないし漢字テストは合格点に届かなかった・・・母さんになんて言おう・・・汗」 そんな状態に似てます。
さて、このような学習不足(ハイバイアス)への対策を調べたところ、いくつか方法を発見したのでここで順番に整理を。
ハイバイアス(学習不足)への対策1:機械学習アルゴリズムを変更する
 一つ目の対策は、そもそも使用する機械学習アルゴリズムを変更すること。
一つ目の対策は、そもそも使用する機械学習アルゴリズムを変更すること。
データのパターンや傾向を表すモデルは、機械学習アルゴリズム(機械学習の方法)によって構築されます。使用する機械学習アルゴリズムによってモデル構築の方法も変わってくるため、モデルの精度が高くなるかどうかというのは扱うデータによって変わってくるのです。
つまり、モデルが学習不足に陥ったなら、そもそも使っている機械学習アルゴリズムに問題があるかもしれないんです。
これはみなさん懐かしの漢字の勉強で例えるなら、目で見るだけで覚えるのか、ひたすら書いて覚えるのか、といったようにより成果が出る勉強法を探すイメージというとわかりやすいかもしれません。
ハイバイアス(学習不足)への対策2:モデルのパラメータの個数を増やす

バナナの個数を増やしてみました
次の学習不足への対策として、機械学習アルゴリズムを変更しない場合はモデルのパラメータの個数を増やす(特徴量の数を増やす)ことが効果的!
そのためには例えば、
- 追加する特徴量を収集または生成する
- モデルの正則化の強さを下げる
必要があります!
お馴染み漢字の勉強に例えると、勉強のやり方は変えないけれど、今までめっちゃ暗い部屋で勉強していた少年が、電気の点いた明るい部屋で漢字を見やすく認識しやすくして学ぶイメージです。(微妙な説明かも・・・ 汗)
ここで、、、何も触れずにスルーしてしまった「特徴量」というこの言葉、機械学習ではよく出てくるんですけど、正直僕はわかっているようなわかっていないような感じで曖昧でした。そこでこれを機に明文化すると、
求めたいものを特徴づけるもののこと。例えば、過去の売上から未来の売上を予測したい場合、天気や気温、湿度等々売上に寄与する情報は、未来の売上げを予測するために必要な特徴量と言う
訓練データにも適合しておらず真の値とのズレ(誤差)も大きい学習不足の状態を、バイアスが高い(ハイバイアス)と表現する。使用する機械学習アルゴリズムを変更したり、モデルの学習に用いる特徴量を増やす、正則化による影響を小さくする、といった対策が効果的。
ハイバリアンス(過学習)への対策
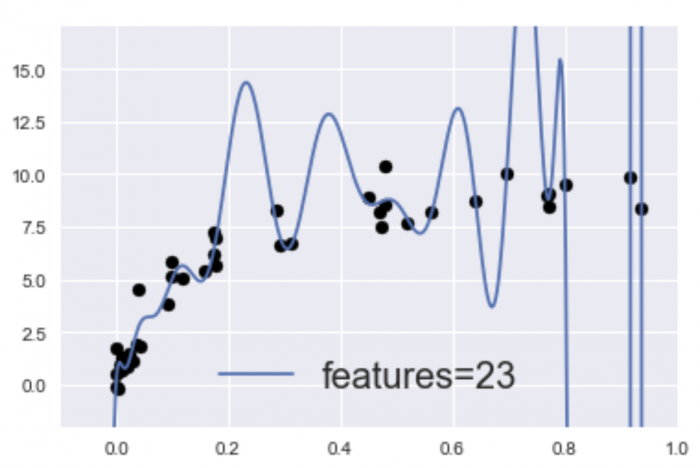
過学習(ハイバリアンス)に陥っているモデルのイメージ
次に、バリアンスが高い状態を見ていきます!まずバリアンスとはバラツキを意味する言葉ですが、バリアンスが高い、ハイバリアンスの状態(過学習)とは、上図のように訓練データに対しては過剰に適合して高い性能を発揮するけれど、検証データ(未知のデータ)に対しては精度が低い状態(汎化性能が無い)です。(ぐにゃんぐにゃんですね(・Д・))
また訓練データとモデル精度の関係性は、次のように訓練データと交差検証による精度に大きな差がある状態です。 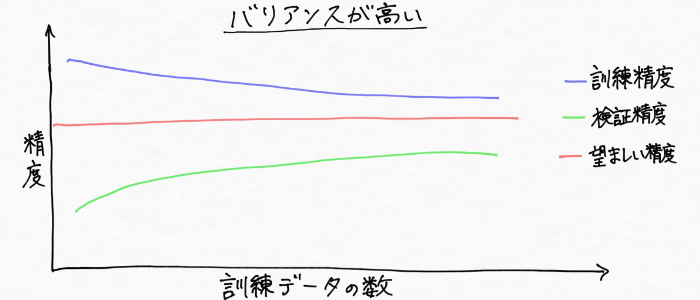
ハイバリアンス(過学習)の原因としては、パラメータの数が多すぎてデータに対してモデルが複雑すぎる状態になっていることが考えられます。
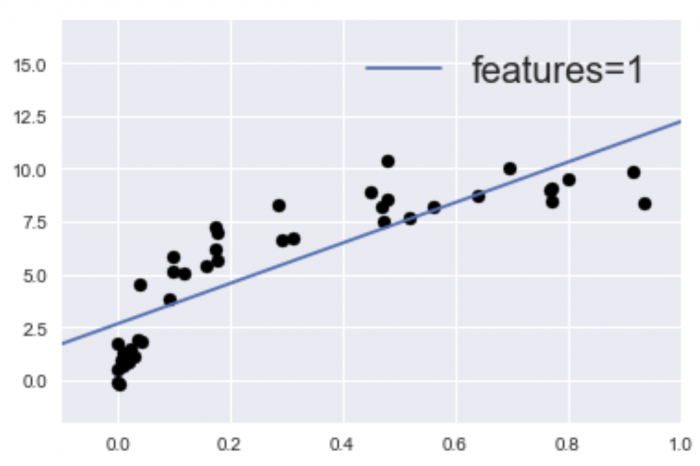
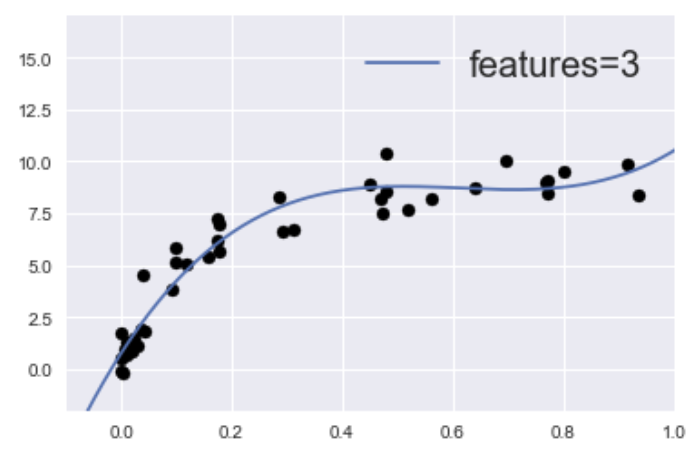
実際、先ほど紹介したこのグラフは、
25個の特徴量(features=23)に適合するよう指示してモデルを構築しました。一方、学習不足のモデルとして前に紹介したこのグラフは、
1個(features=1)の特徴量に適合するよう指示してモデルを構築しています。
ぐにゃんぐにゃんのモデルが出来上がってしまっているハイバリアンスの状態(過学習)の対策には、以前調べたように(詳細はこちら https://aizine.ai/overfitting0206/)「訓練データの数を増やす」、「正則化を実施してモデルの複雑さを抑制する」などがあります。
機械学習のモデルによっては正則化がされていないものもあるんですが、そうしたモデルの精度を上げるには、特徴量の個数を減らすことも効果的。
ちなみに学びを深めて行く最中に「特徴量」、「次元」、「説明変数」と似たようなニュアンスの言葉の使い分けに混乱して困りました。(これらは今まで同じようなもんだな・・・と軽い認識で進んできたので 汗)
曖昧な状態が気持ち悪かったので調べていったところ、特徴量の個数が「次元」(だと分かりました)。
そして次元を減らすとは目的変数に作用する説明変数(パラメータの数)を減らすということで、例えば特徴量の説明で記載した未来の売上を予測する例で言えば、売上げ(目的変数)に作用する天気や気温、湿度など(説明変数)のいずれかを使わずにモデルを学習させるというわけです。
つまり、整理すると、、、、
特徴量の個数 = 次元 = 説明変数の数
スッキリ!! o(≧▽≦)o
このように目的変数に作用する説明変数の数(特徴量の個数、次元)を減らすことで、モデルが適合しようとする要素が少なくなる分、形がシンプルになってハイバリアンス(過学習)を解消することへとつながるんです。・・・なるほど!!
訓練データと交差検証の精度に大きな差がある過学習の状態をバリアンスが高い(ハイバリアンス)と表現する。モデルの学習に使用する特徴量を減らしたり、正則化による影響を強めるなどの対策が効果的。
汎化性能の高いモデルを作るとは、バイアスとバリアンスがちょうど良い点を見つけること
ふうっ・・・。やっと今回のコンテンツ折り返し地点(ぐらい)まできました。ここで一旦、バナナやコーヒーなどご自身のお好きなものを取りにいって後半戦に備えましょう(^^) バイアスとバリアンスっていう言葉が似ているため僕は途中かなり混乱しました 汗
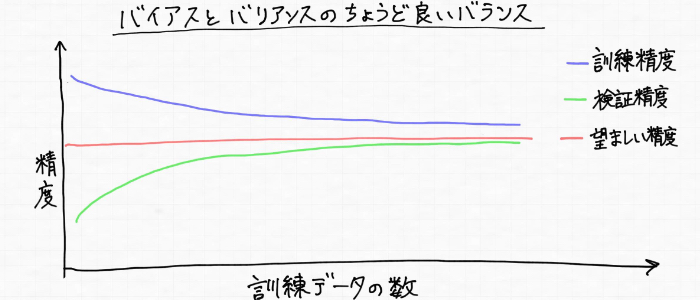
ここまではハイバイアス(学習不足)とハイバリアンス(過学習)を表す学習曲線を見てきたわけですが、モデルの望ましい状態を表す学習曲線は次のように訓練データ(青)に対しても検証データ(緑)に対しても高い精度を示す状態です。
そしてこの状態のモデルの形は、次のようなイメージ。
汎化性能の高いモデルのイメージ
ガチガチでもなく、ぐにゃんぐにゃんでもなくちょうど良く滑らかですよね!!バイアスが高すぎでもダメで、バリアンスが高すぎでもダメ。つまり汎化性能の高いモデルを得るとは、バイアスとバリアンスとの適切なトレードオフの場所を見つけることになります!
Pythonで学習曲線を描いてみた

ここまではイメージ図としての学習曲線ばかりだったので、Python(プログラミング言語)を用いて実際に学習曲線を作ってみる。というのも、実は先日松島編集長から、、、
文章ばっか書いてるけど本当にAI(人工知能)の勉強してんの?プログラミングはどうなの?
もちろんやってます!!
じゃあコンテンツに載せてった方がいいよ。口だけなら誰でもできるからね。

と、こんなやりとりがあって悔しかった一方、松島編集長の言ってることは正しい・・・。
だから文章を書いてるだけじゃなくて今後はコードも掲載していくことにしました!もちろん、コードに興味のない方もいることは百も承知なので、コードを読み飛ばしても大丈夫なように整理していきます!
(今みなさんがご覧になっているこのメディアAIZINEの方針は、「誰もが読んで楽しめるもの」です)
そして、ここから学習曲線を作っていくんですが、、、、
乳がんの診断データ(合計569人分)が含まれたデータセット(データの集まりのこと)が公開されているので今回はこれを利用します。これは腫瘍の画像に基づいて腫瘍の「平均半径」や「外周の長さ」など30個の測定項目(特徴量)が一人分ずつそれぞれデータとしてまとめられたデータセットです。
※データセットの中身を一部紹介すると、下記のようになっています↓
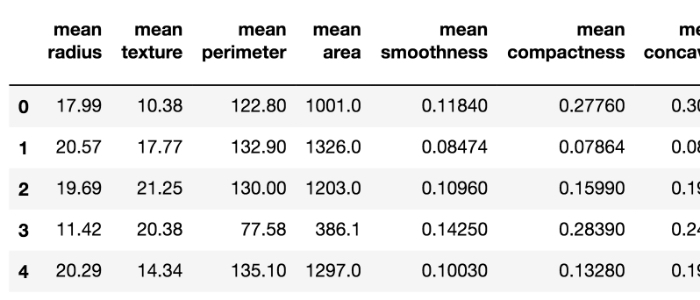
1行ずつ腫瘍の特徴がまとめられています。30個の特徴量をまとめた569人分のデータがあるので、569行 × 30列のデータセットです。
このデータセットに対して、診断した腫瘍が悪性か良性かを予測する機械学習モデルを実際に構築してそのモデルの学習曲線(learning curve)を表示してみたところ次のようになりました。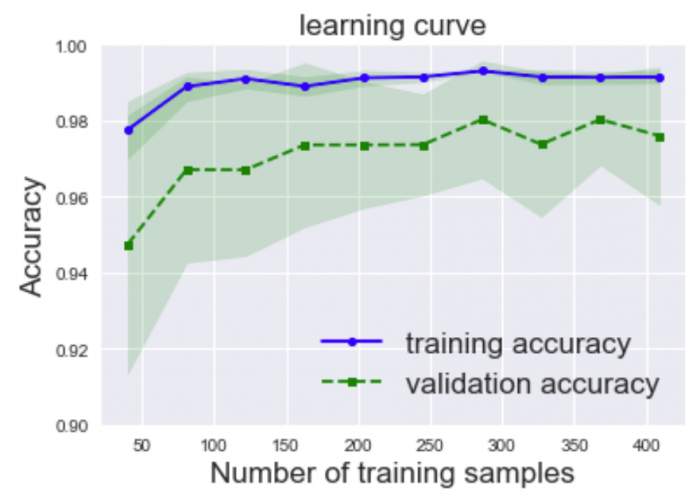
・Number of training samples:訓練データの数
・Accuracy:モデルの予測による正解率
・training accuracy:訓練データに対する正解率
・validation accuracy:検証データに対する正解率
※色の帯は、正解率の標準偏差を示しており、標準偏差とは値のバラツキを見る指標のこと
この学習曲線を見ると訓練データと検証データでのモデルの性能に差があるので、訓練データの小さな過学習があると判断できます。(今回は参考書を真似しながらグラフを作成して理解を深めました)
学習曲線を生成する際に使用したコード
コードを見て吐きそうになった方は、こちらはスルーしてください。プログラミングに興味がなかった昔の僕が実際そうでしたので、大変お気持わかります(><)。
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn; seaborn.set()
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.learning_curve import learning_curve
from sklearn.cross_validation import train_test_split
#データの読み込み
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data',header=None)
#データを目的変数と説明変数に分割する
X = df.loc[:,2:].values
y = df.loc[:,1].values
#カテゴリカル変数を連続直に変換する
le = LabelEncoder()
y = le.fit_transform(y)
#訓練データとテストデータにデータを分割
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.20, random_state=1)
#パイプラインを用いてデータのスケール変換を行い、ロジスティック回帰を準備する
pipe_lr = Pipeline([('scl',StandardScaler()), ('clf',LogisticRegression(penalty='l2',random_state=0))])
#learning_curve関数で交差検証による正解率を算出する
train_sizes, train_scores,test_scores = \
learning_curve(estimator=pipe_lr, X=X_train, y=y_train, train_sizes=np.linspace(0.1,1.0,10), cv=10, n_jobs=1)
train_mean = np.mean(train_scores,axis=1)
train_std = np.std(train_scores,axis=1)
test_mean = np.mean(test_scores,axis=1)
test_std = np.std(test_scores,axis=1)
#学習曲線を描画する
plt.plot(train_sizes,train_mean, color='blue', marker='o', markersize=5, label='training accuracy')
plt.plot(train_sizes,test_mean, color='green',linestyle='--', marker='s', markersize=5, label='validation accuracy')
#fill_between関数で平均±標準偏差の幅を塗りつぶす
#トレーニングデータのサイズtrain_sizes,透明度alpha、カラー'blue'を引数に指定
plt.fill_between(train_sizes,train_mean+train_std,train_mean-train_std,alpha=0.15,color='green')
plt.fill_between(train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15,color='green')
#グラフの見た目を整える
plt.title('learning curve', fontsize=17)
plt.xlabel('Number of training samples', fontsize=17)
plt.ylabel('Accuracy', fontsize=17)
plt.legend(loc='lower right', fontsize=17)
plt.ylim([0.90,1.0])
#グラフを表示
plt.show()
ハイパーパラメータとモデルの性能の変化を視覚的に確認できる検証曲線
学習曲線について情報を整理してほっと一安心していた僕は、熱いコーヒー入れて一息つきながらまた手元のAI(機械学習)の参考書をペラペラとめくっていた(澄ました顔で)時、またコーヒーを吹き出しそうになった。
け、検証曲線!???
正直なところ過学習への対策は今回学習曲線だけで終わると思ってたんですが、学習曲線に関係の深い「検証曲線」とやらも見つけたのでこちらについても整理、理解をすることに決めました!
学習曲線の場合は「訓練データの量」と「モデルの性能」の関係性を見ていくものだったけど、この「検証曲線」は「訓練データの量」ではなくモデルの「ハイパーパラメータの値」に伴ってモデルの性能がどう変化するかを見ていくツールらしいです。(なるほど!!)
※ハイパーパラメータ:人が調整をする必要のある、機械学習のモデルが持っている変数
ここからも少し細かい話になるので、結論だけを早く知りたい方は本章の最後にある「ここまでのまとめ」をお読みください(^^)
検証曲線を描いてみた
 前述の腫瘍を悪性か良性かに分類するデータセットを用いて検証曲線を書いてみる。
前述の腫瘍を悪性か良性かに分類するデータセットを用いて検証曲線を書いてみる。
今回はロジスティック回帰という教師あり学習(分類)に当たる機械学習アルゴリズムを元にモデルを作ってみる。腫瘍を良性と悪性に分けようとした時、ロジスティック回帰のハイパーパラメータ(パラメータCと呼ばれる)を7つの値(0.001、 0.01、0.1、 1.0、 10、 100、1000)に変えてそれぞれ試してみると、モデルの性能は次のように変化しました。
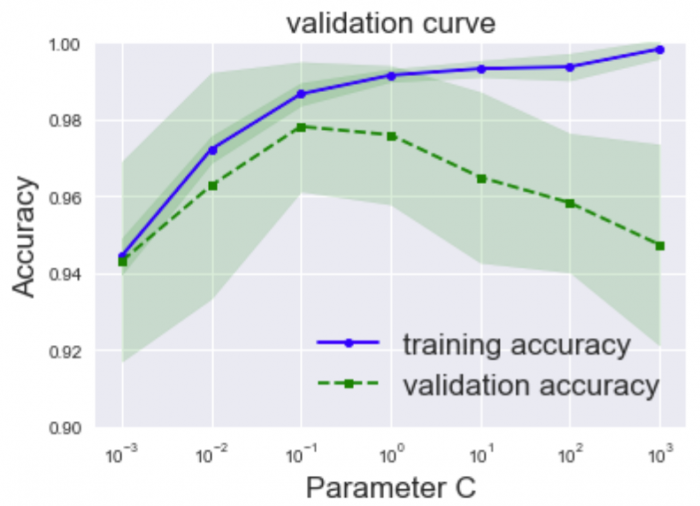
・Accuracy:モデルの予測による正解率
・training accuracy:訓練データに対する正解率
・validation accuracy:検証データに対する正解率
・Parameter C:パラメータC(ハイパーパラメータ)
上記のグラフを見ると、
パラメータCの値をどんどん大きくしていくと、訓練データと検証データでのモデル性能の差がどんどん開いていく、つまり過学習に陥っていく傾向がわかります。適切なハイパーパラメータの値はどこかといえば、、、訓練データと検証データ共に性能が高く、かつ両者の性能の差が小さい0.1あたりにパラメータCを設定すると良さそうだと判断できますよね!!
このように検証曲線を見ることで最適なハイパーパラメータを設定できるんですね〜
ちなみに調べていて知ったのですが、ロジスティック回帰のパラメータCには「逆正則化パラメータ」という名前がついていて、値を強くすればするほど正則化の影響を弱める(モデルの複雑度が上がる)作用が働きます。
検証曲線を生成する際に使用したコード
コードを見て吐きそうになる方はもちろんスルーしてください。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn; seaborn.set()
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.learning_curve import validation_curve
#データの読み込み
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data',header=None)
#データを目的変数と説明変数に分割する
X = df.loc[:,2:].values
y = df.loc[:,1].values
#カテゴリカル変数を連続直に変換する
le = LabelEncoder()
y = le.fit_transform(y)
#訓練データとテストデータにデータを分割
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.20, random_state=1)
#パイプラインを用いてデータのスケール変換を行い、ロジスティック回帰を準備する
pipe_lr = Pipeline([('scl',StandardScaler()), ('clf',LogisticRegression(penalty='l2',random_state=0))])
#探索したいハイパーパラメータを準備する
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
#learning_curve関数で交差検証による正解率を算出
train_scores,test_scores = \
validation_curve(estimator=pipe_lr, X=X_train, y=y_train, param_name='clf__C', param_range=param_range, cv=10)
train_mean = np.mean(train_scores,axis=1)
train_std = np.std(train_scores,axis=1)
test_mean = np.mean(test_scores,axis=1)
test_std = np.std(test_scores,axis=1)
#学習曲線を描画する
plt.plot(param_range,train_mean, color='blue', marker='o', markersize=5, label='training accuracy')
plt.plot(param_range,test_mean, color='green',linestyle='--', marker='s', markersize=5, label='validation accuracy')
#fill_between関数で平均±標準偏差の幅を塗りつぶす
#トレーニングデータのサイズtrain_sizes,透明度alpha、カラー'blue'を引数に指定
plt.fill_between(param_range, train_mean + train_std, train_mean - train_std, alpha=0.15,color='green')
plt.fill_between(param_range, test_mean + test_std, test_mean - test_std, alpha=0.15,color='green')
#グラフの見た目を整える
plt.title('validation curve', fontsize=17)
plt.xscale('log')
plt.legend(loc='lower right', fontsize=17)
plt.xlabel('Parameter C', fontsize=17)
plt.ylabel('Accuracy', fontsize=17)
plt.ylim([0.9,1.0])
#グラフを表示する
plt.show()
検証曲線とは、モデルのハイパーパラメータの値に伴ってモデルの性能がどう変化するかを示したグラフ。検証曲線を見ることで、汎化性能を高められる適切なハイパーパラメータの値を視覚的に探索できる。
最適なハイパーパラメータを自動で探索してくれるグリッドサーチ
 さて、ここまでモデルの汎化性能を高めていくために役立つ「学習曲線」と「検証曲線」を見てきて理解が深まったのでめでたしめでたし、、と終わりたいところなんですが、ここでちょっと気がかりなことが・・・。
さて、ここまでモデルの汎化性能を高めていくために役立つ「学習曲線」と「検証曲線」を見てきて理解が深まったのでめでたしめでたし、、と終わりたいところなんですが、ここでちょっと気がかりなことが・・・。
機械学習アルゴリズムにもハイパーパラメータにも色んな種類があるし、複数のハイパーパラメータを指定しなきゃいけない場合もある。
適切な値の組み合わせって毎回手を動かして一つずつ確かめなきゃいけないの?それってめっちゃ大変やんか・・・
という気がかりです。
考えてみると、、2つのハイパーパラメータを設定する必要があるモデルの場合は、2つの値それぞれに対して例えばさっきみたいに7つ(0.001、 0.01、0.1、 1、 10、 100、1000)全部の組み合わせを確認しようとしたら、全部で合計7×7=49通りもあるよ・・・Σ(゚д゚lll)
49回試したらもちろん結果は出るんですけど。。。
そんな悩みを解決してくれる便利なツール、大変ありがたいことにありました!
その名もグリッドサーチ!!
グリッドサーチは、ハイパーパラメータの「最適な」組み合わせを見つけ出すことによってモデルの性能をさらに改善することに役立つ手法です。
これは例えば、「これだけの食材用意しといたから、あとは一番美味しく料理できる適切な塩加減とか醤油の量の組み合わせを勝手に調べといて!!よろしく!」みたいな感じで、
「ハイパーパラメータの候補用意しといたから、あとは最適な値の組み合わせ自動で調べといて!よろしく!」みたいに済ませられる大変便利なツールがグリッドサーチです!
ただ、たくさんの組み合わせをコンピュータが頑張って計算処理するので計算時間が長くかかってしまうのが懸念点としてあります(>_<)
グリッドサーチを使ってみた
そして、次はサポートベクターマシンという機械学習アルゴリズムに対して、3つのハイパーパラメータの適切な組み合わせを見つけるようにグリッドサーチを利用して動かしてみると、、、
コードはもうお腹いっぱいだわと思われた方はスルーしてください。
#グリッドサーチによるハイパーパラメータチューニング
import pandas as pd
from sklearn.svm import SVC
from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import train_test_split
from sklearn.model_selection import GridSearchCV
#乳がんの診断データの読み込み
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data',header=None)
#データを目的変数と説明変数に分割する
X = df.loc[:,2:].values
y = df.loc[:,1].values
#カテゴリカル変数を連続直に変換する
le = LabelEncoder()
y = le.fit_transform(y)
#訓練データとテストデータに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20,random_state=1)
#探索したいハイパーパラメータの組み合わせを指定する
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
param_grid = {
'C' : param_range,
'gamma' : param_range,
'random_state' : [0, 1, 2, 3, 4, 5]
}
#サポートベクターマシンの最適なハイパーパラメータの組み合わせを10分割交差検証によって探索することを指定
grid_search = GridSearchCV(SVC(), param_grid, cv=10)
#グリッドサーチを用いて最良の性能を出すパラメータを選出し、そのパラメータを用いて訓練データで学習する
grid_search.fit(X_train, y_train)
print(f"テストデータに対するモデルの精度:{grid_search.score(X_test, y_test):.3f}")
print(f"モデルのハイパーパラメータ : {grid_search.best_params_}")
#Out
テストデータに対するモデルの精度:0.956
モデルのハイパーパラメータ : {'C': 1.0, 'gamma': 0.001, 'random_state': 0}
最適なハイパーパラメータの組み合わせ(この場合は6×6×6 = 216通りの中から)を自動的に見つけてくれました!グリッドサーチ大変ありがたいです!!
グリッドサーチは、ハイパーパラメータの値の「最適な」組み合わせを見つけ出すことによりモデルの性能をさらに改善することに役立つ手法で、たくさんある組み合わせを人間の代わりにコンピュータが自動で見つけてくれる大変便利なツールです。
まとめ

一箇所に「まとめ」たバナナ
さて、今回はAI(機械学習)でよくある問題過学習への対策として有効な「学習曲線」に始まり、どのハイパーパラメータが良さそうかを確認できる「検証曲線」、そして最適なハイパーパラメータを探してくれる便利な「グリッドサーチ」について整理してきました!
改めて整理してみると、
- モデルが過学習に陥っている状態はハイバリアンスと表現され、学習不足の状態はハイバイアスと表現される。
- 汎化性能の高いモデルを作るとは、バイアスとバリアンスがちょうど良い点を見つけることである
- 学習曲線を見れば過学習か学習不足かを判断でき、今後の行動の判断に役立てられる
- 検証曲線を見ればモデルの性能の変化とハイパーパラメータの変化の関係を確認できる
- グリッドサーチによって最適なハイパーパラメータを自動で探索できる
というポイントがありましたよね!
今回情報を整理しながら強く感じたのは、「あっ、これ前見たことある・・・でも全然理解してないし、わかったことにしたままずっと放置してきてたわ」そんなものばかりだということでした。とほほ・・・。
これはAI(機械学習)に関する学びに限らず、例えば一度本を読んで内容を理解した気になったり、人との会話で一度聞いただけでわかった気になってしまいがちな僕の姿勢に似ている。。。(>_<)
以前勤めていた会社でよく
「わかりましたって言うな!わかるはずがないんだよ!」
と何度も僕は叱られていました。当時はその言葉の意味がよくわかりませんでしたが、今思えば大変貴重なフィードバックを頂けていたことにとても感謝しています。ある情報の重要性やその価値、意味などは、受け取る人の状況や本人が体験してきた経験によって受け取れる情報量が全く変わってしまうものでしょう。何事もわかった気にならずこれからも学びを続けていきたいです!
次回は「モデルの性能評価」について理解を深めていく予定です(今回みたいに見落としに気づけば急遽予定を変更するかもですが)。興味のある方、またぜひお会いしましょう!!

<参考>
・Andreas C. Muller and Sarah Guido (2016). Introduction to Machine Learning with Python: A Guide for Data Scientists. O’Reilly Media, Inc. (アンドレアス・C・ミューラー、サラ・グイド 中田 秀基(訳)(2017). Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎 株式会社オライリー・ジャパン)
・Sebastian Raschka(2015). Python Machine Learning. Packt Publishing. (株式会社クイープ、福島真太朗(訳)) (2016). 『Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)』

AI(人工知能)って「なにそれ美味しいの?」ってレベルだった僕が、AIエンジニアを目指してステップを踏んだり踏まれたりしている記事を書いてます。よかったら読んでみてください(実話)。



コメントをどうぞ