
僕が会社をクビになってまで目指しているのはAI(機械学習)エンジニアですが、AI(機械学習)を実装しようとする際には誰もが直面する問題があります。それは一般的に「過学習」や「過剰適合」、「オーバーフィッティング」と呼ばれている現象で、よく起こるのこの問題は僕たちのこんな経験に似ています。
学びを深めてきたけれど、いざ実践となると全然応用がきかずにダメだった
こうした悔しい出来事を体験したことのある人は以外に多いかもしれません。(僕はそんな体験ばっかりが記憶にあるんですけど・・・汗)AI(機械学習)も同じように、頑張ってモデル(数式でデータのパターンやルールを表したもの)を構築したももの「学習させたけど全然使えないじゃん」っていう問題が簡単に起こります。
こうした問題への対策は「理解しておかないと実務にならないからヤバイ!」ってことだけは僕知ってます。けれど、僕の今の理解ではこの過学習がなんで起きて、どういうもので、どう対策したらいいのか?なんてことはちゃんと理解できてません。。。
(だったらなんでこんな大事なことを今まで理解せず放置してきたんだよ・・・という声が聞こえてきそうで苦しいです 汗)
わからないことや難しそうなことは後回してしまいがち。だからこそスキルの無い僕は過去に会社をクビになって今こんな状態になってます・・・。その時の話はコチラ↓

こうした背景もあって、「もう知識を曖昧にしておくのは嫌だ!!」と思ったので、そこで今回は過学習の詳しい内容や対策について調べて理解していくことにしました!
※機械学習:AI(人工知能)を実現するために、現在中心となって使われている一つの技術。
過学習って何?と調べていったら僕のことを指してるようで複雑な気持ちになった
 毎回理解が曖昧なままわかった気でいて後日大変な目にあう僕なので、一つ一つ丁寧に理解していくことにしています!!
毎回理解が曖昧なままわかった気でいて後日大変な目にあう僕なので、一つ一つ丁寧に理解していくことにしています!!
「よっしゃあ!!今回もどんどん理解していったる!!」と意気込みながら早速調べて行ったところ、、、AI(機械学習)を実装する場合によくある問題「過学習」とは、
「持っている情報の量に比べて過剰に複雑なモデルを作ってしまうこと」
<参考文献>アンドレアス・C・ミューラー、サラ・グイド(著)中田 秀基(訳)(2017).『Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎』株式会社オライリー・ジャパン.
という記述を発見!!
・・・・・・。
・・・・・・。
「持っている情報の量?」「複雑なモデル?」
・・・ワカリマセン。

いきなり壁にぶち当たってしまったんですが、「一個ずつ紐解いていけばクリアできるはず!解けない問題はないんじゃいっ!」と信じて、まずはこれまで自分が整理、理解してきた内容を改めて確認しながら進んでいくことにしました。
まず、
以前調べた(第3話)ことがあるモデルとは、数式で「事象を簡単にして本質を表したもの」のことで、データのパターンやルールを数式で表したものだった。
情報:分析対象が持つ性質や特徴のこと
データ:情報を何らかの測定法を用いて数値や文字にしたもの
例えば、結婚年数と愛の深さの関係を例に出すと、情報は夫婦間の愛そのものであり、データとはその夫婦間の愛をアンケートなどの何らかの測定法で数値や文章にしたもの
例えば愛の深さと結婚年数の関係を調査したと仮定して次のようにグラフ上に落とし込んだとする。
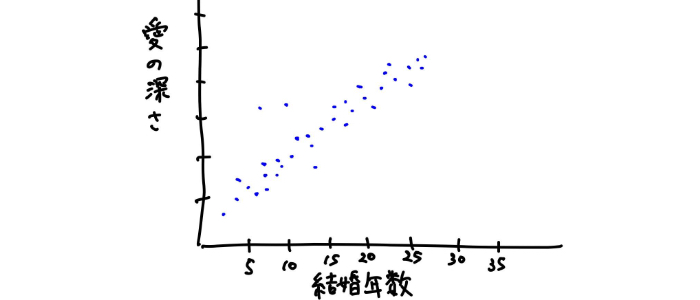
このようなデータの傾向やパターンは、こんな風に直線(y = ax + b)で表現できそう。
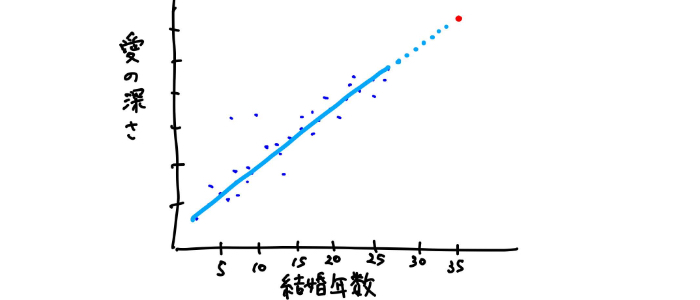
このように適切にデータの傾向やパターンをつかんだ直線(モデル)を引くためには、様々種類がある機械学習アルゴリズム(機械学習の手法)から一つを選んで、それに基づいてモデルを学習(データからパターンを掴んで適切な線を引く)させていく必要があった。
そしてこのようにモデルを学習させていくために使う「学習(訓練)データ」と、学習したモデルが本当に信用できるの?どうなん?と確かめることに使う「テストデータ」の二つが必要だった。
(詳しくはコチラ↓)

そんなことを振り返りつつ、「複雑なモデルって、、複雑な形をしているモデルのこと?」とそんな予想をしながら調べていたところ、過学習のわかりやすい解説を見つけて理解するに至りました!
例えば、自分が何らかのお店で働いていて過去の売上データを元に、月毎に将来の売上げを予測したかったとしましょう。売上には、天気や気温、湿度などが関係しそうと想像できます。
ここで一旦、必要な知識の整理を。
AI(人工知能)の分野では求めたいものを「目的変数」、目的変数に作用する変数を「説明変数」と表現するようで、つまり今回の例では、
となります。
「変数」という言葉についても僕ははっきり理解してる!とは正直言い難かったので確認をしておきます。
変数とは、ケース毎に変わり得る数。天気や気温は毎日数値が変わるし、それに応じて売上げも変わっていく。
以上を踏まえた上で、次のように月ごとの売上げ(目的変数)と天気や気温、湿度など(説明変数)の関係を、毎年毎年グラフ上に点として記録していったとして、、、例えばこんな風に記録できたとします。
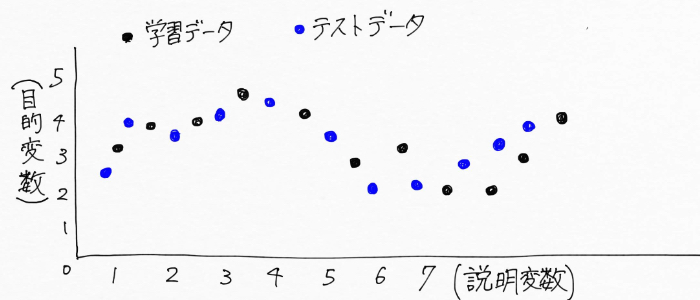
この図の場合、
テストデータ:未知のデータ、まだ手元にはない未来のデータ
となる。(理解しやすいよう、テストデータの点を記してます)
「学習データから傾向やパターンを掴んで未来の売上げを予測できるモデルをつくる」、つまりデータの傾向を踏まえた線を引くと、、、こんな風に線が引けそう(線を引く=モデルの予測値)
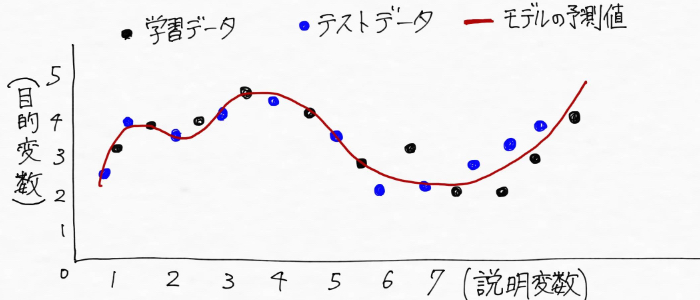
説明変数 :天気、気温、湿度など
この図では、学習データ(過去の売上と天気、気温、湿度などの関係)とテストデータ(未来の値)の両方に対して、モデルがデータの傾向を上手くつかんで適合していることがわかる。
一方過学習という状態は、次みたいに学習データ(過去の売上と天気、気温、湿度などの関係)にだけ適合するぐにゃぐにゃの複雑な形をしていて、テストデータ(未来の値)の予測には全然対応していない状態(全然ダメじゃん!!)というわけ。
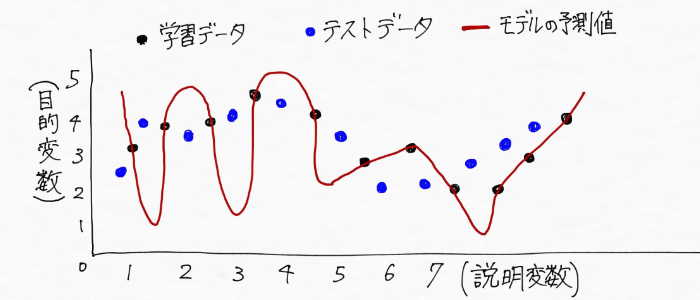
こんなモデルでテストデータ(未来の値)を予測しても全く当たらないから、てんで使い物にならない。
これで過学習の意味についてはスッキリ!(僕が)
ちなみに、過学習という学習データにしか対応できない状態とは逆に、未知のデータにも対応できるモデルのことを「汎化性能(汎化能力)があるモデル」と言います。
思い返せば、僕は運よくAI開発企業に入社できたんですが、参考書ばっかり読んできたため実践スキルが足らず1ヶ月半で左遷されてしまいました。これは参考書に特化した過学習だった、、とも言えるかもしれません 汗
過学習とは、「学習に使ったデータに対してはきちんと予測できるけど、知らないデータに対しては全然当たらない」という実用性を全く伴っていない状態のこと。
こんな状態を説明する用語として「過学習」の他、「過剰適合」、英語読みで「OverFitting(オーバーフィッティング)」などとよんだりする!!
過学習への3つの対策〜「学習データ数を増やす」「モデルを簡単なものにする」「正則化を実施する」
過学習の理解が明確になったからもう満足!・・・とはなりません!「過学習はわかったけど・・・で、どう対策したらいいの?」というようにここからがさらに大事です!
続いてAI(機械学習)を実装する際によく問題となる過学習への対策を調べていくと・・・対策には大きく3つあることが判明!
気になる過学習への対策がこれです!!じゃじゃーーーん!!
①学習(訓練)データの数を増やす
②ハイパーパラメーターを調整する(モデルを簡単なものにする)
③正則化を実施する
①はイメージがつきやすそうな気がするけど、②と③が今回のボスキャラになりそうな予感(>_<)・・・一個ずつ自分の言葉にしながら理解を深めていきます。
過学習への対策その1:学習(訓練)データの数を増やす
①学習(訓練)データの数を増やす
②ハイパーパラメーターを調整する(モデルを簡単なものにする)
③正則化を実施する
改めて、機械学習はAI(人工知能)を実現するための技術の一つで、データからデータに潜むパターンや傾向を掴んでいって(モデルを構築する)未知のデータの予測や判定をする技術。
学習データが少なければ予測精度の高いモデルはつくりづらいですが、学習データの数を増やすことで精度を上げることが可能です。言葉だけではわかりづらいので、イメージ図で視覚化してみると、、、
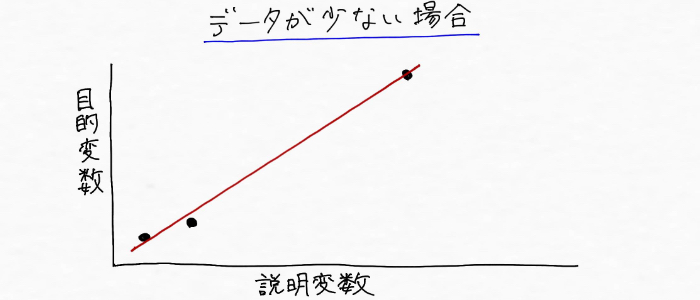
まずモデルの学習に使えるデータが少ない場合は、
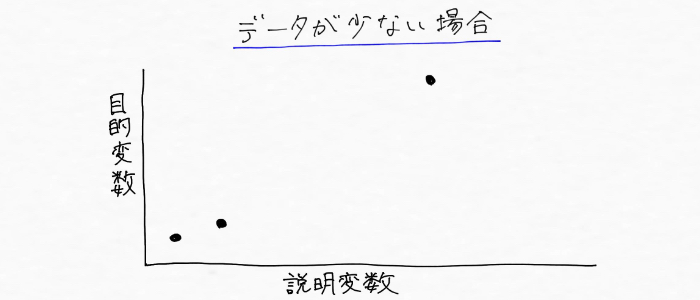
こんな風に線を引くことになりそう。
一方、次のように学習するデータ数が増えたら、
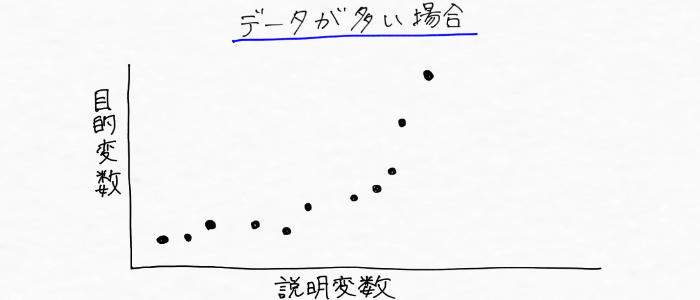
こんな風に線を引くことになりそう。
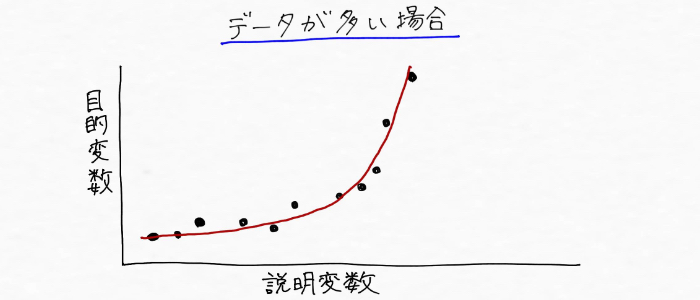
さっきと全然形違うやん・・・。
つまり、学習データを増やすことでより正確にデータの傾向を掴めるようになっていくので、予測精度の高いモデルを構築できるというわけ。なので、AI(機械学習)開発において過学習という問題が起こった場合は、学習データをもっと準備できないか考えていくことが必要になる!!
過学習の対策の一つが「学習データの数を増やすこと」。手元にある学習データの量が少ないことが理由でデータの傾向を十分に表現しきれていない場合があるため、学習データの数を増やすことが過学習を避け、汎化性能を高めることへ効果的である。
過学習への対策その2:ハイパーパラメーターを調整する(モデルを簡単なものに変更する)
①学習(訓練)データの数を増やす
②ハイパーパラメーターを調整する(モデルを簡単なものにする)
③正則化を実施する
はい、来ました。。。今回のボス戦一発目。これは理解に手こずりそう・・・汗
まず、絶対に僕の日常会話では出てこない単語「ハイパーパラメーター」の理解からしていく。調べてみると、
機械学習のモデルには、モデルの複雑さを調整する「ハイパーパラメーター」と呼ばれるパラメーターが存在している
ハイパーパラメーターとは機械学習のモデルが持つパラメーターの中で人が調整をしないといけないパラメーターのこと
という解説を発見!!しかし、「パラメーター」も聞きなれない言葉。調べてみると「パラメーター」とは変数を意味している言葉で、変数とはケース毎に変わり得る数!(さっき調べました(^^))
一方「ハイパー」の日本語訳は「極超」となって「ハイパーパラメーター」はつまり、、、「極超変数」となってますます意味がわかんねえ。

これは流石に日本語訳して考えてもあんまり意味がなさそう(たぶん適切な日本語訳が無い気がする)。なので、細かいことは考えず「ハイパーパラメーター」の意味するものを色々調べる。
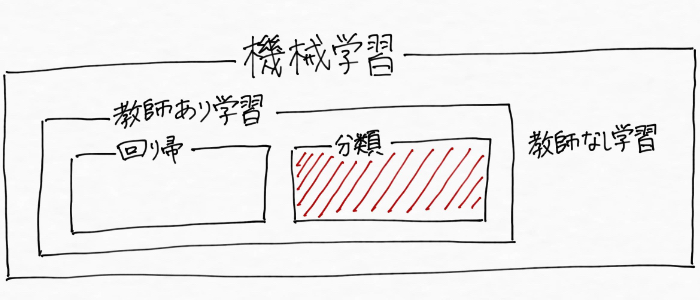
具体的に整理していってなんとか理解できたのですが、例えば、機械学習の一つである教師あり学習(分類)には、色んな機械学習アルゴリズム(機械学習の方法)があります。その中の1つが「決定木(けっていぎ)」。
今まで「けっていき」っていう呼び方だと思って間違えて読んでました 汗
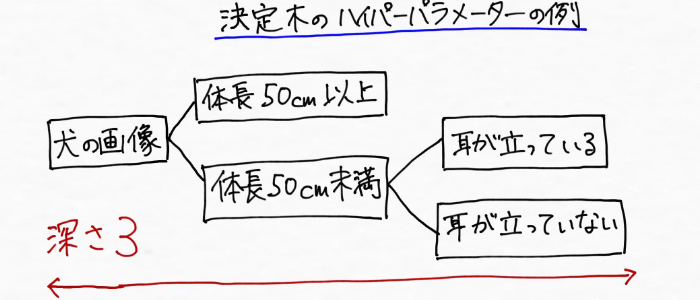
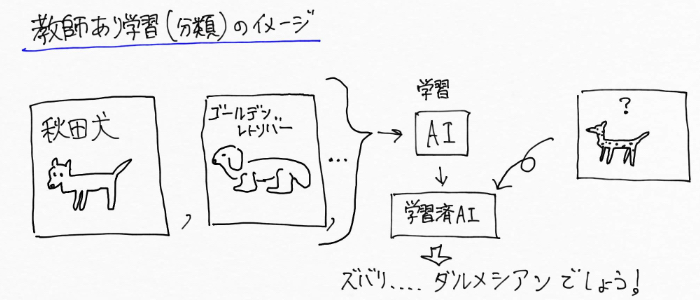
決定木とは、例えば名前のわからない犬の名前を「これ何犬?」と尋ねると「〇〇犬!」と教えてくれるAI(機械学習)をつくろうとした場合、決定木のモデルは次のように段階的に犬の特徴を見つけていくイメージになります。
もっと階層を増やせばこんな風に犬の画像を判定するために必要な特徴が増えていきます。
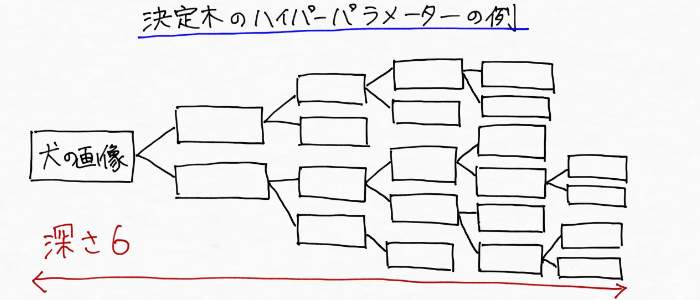
このように、決定木モデルは階層がどんどん深くなっていくにつれて犬の細かな特徴(目的変数を分類しやすい特徴)を段階的に見つけていくわけです。これはつまり、階層が増えるほど、決定木モデルがごちゃごちゃして複雑になっていくということなんです。
そして、この時の木の深さが「ハイパーパラメーター」の1つであることが調べた結果判明しました!この「ハイパーパラメーター」つまり階層の深さを変更することで、モデルの複雑さを調整できる訳です。
じゃあ具体的にどんなふうに調整していくんだ!? と思ったので、さらに調べていくと、「交差検証」というものを使うことが見えてきました。
話が少し込み入ってきたので、図に書いて整理してみるとデータごとの関係はこんなイメージに。
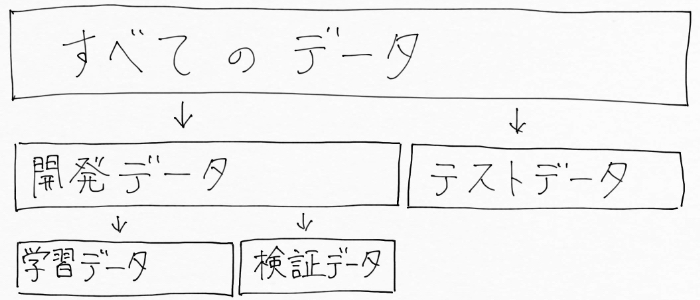
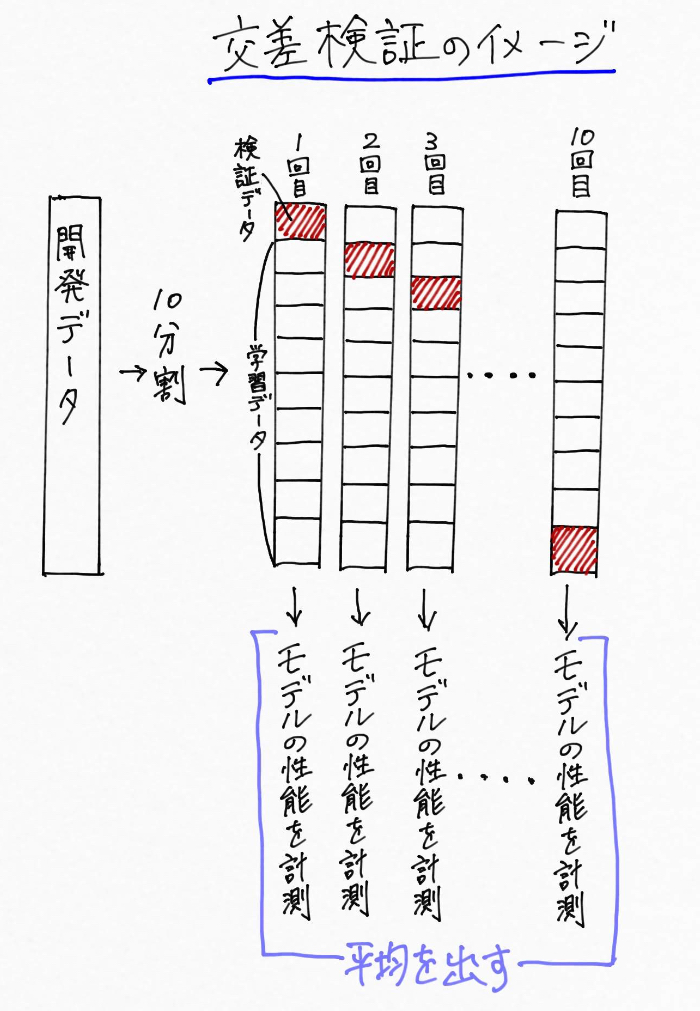
さてさて、このハイパーパラメーターを調整するために行う「交差検証」なんですが、データを「学習データ」と「検証データ」に分割した後、行うことは次の通り。
例えば開発データを10分割して、「9割の学習データ」、「1割を検証データ」とする
↓
「学習データ」で任意のハイパーパラメーターを設定したモデルの学習を行う
↓
「検証データ」でモデルの性能を評価する。
↓
このプロセスを10回繰り返して性能の平均をとる。
少しややこしいのでまとめるとこんなイメージ。
※画像長いので注意です
そして、「なんでこんなややこしいことをするのか!?」と最初僕は疑問に思ったんですが(多分みなさんも)、この疑問を解消するためには極端な例で考えたところスッキリしました!!
交差検証には、「学習データ」と「テストデータ」へとただ分割するよりも良い点があるんです。
例えば決定木の事例で出てきた犬の名前を教えてくれるAI(機械学習)を実装しようとしていて、
「学習データ」にはクラス(分類対象のカテゴリ)分類が難しそうな雑種犬の画像ばかりが入り、「テストデータ」には分類がしやすい特徴がはっきりした犬の画像ばかりが入っていたら、、、モデルの精度はめちゃめちゃ高くなる。だって解く問題(テストデータ)が簡単なんですもの。
逆に、クラス分類が難しそうな雑種犬の画像が全てテストデータに入っていれば、モデルの精度はめちゃくちゃ低くなってしまう。
その点、交差検証を使えば全ての犬の画像が必ず一度はテスト検証データとして利用されます。つまり、交差検証によって平均的に良い性能結果を出すモデルは、全てのデータに対して良い汎化性能を示すことになる!というわけです。
さて、前述したように決定木の階層の深さがハイパーパラメーターでした。
(再掲)
「階層が3の時の決定木モデルの性能はどうだろうか?」「5の時の性能はどう?」などと深さ(ハイパーパラメーター)を調整しながら、上記の交差検証のプロセスを何度も繰り返して、適切な階層の深さ(ハイパーパラメーター)を決定していきます(少し面倒 汗)
モデルの性能の良い結果が出るハイパーパラメーターが決まったら、次はテストデータを用いて「未知のデータに対しても予測ができるか?」ということを確かめていく。
これはつまり、前述の犬の名前を返す決定きモデルの事例でいうなら、名前不明の犬の画像(テストデータ)を渡して、どれくらいの精度で予測(正しく犬の名前を返してくるか)を評価していくことになります。
かなりややこしくなったので、ここまでの一連の流れを図にまとめるとこんな感じです。
※今度も下に長い画像です
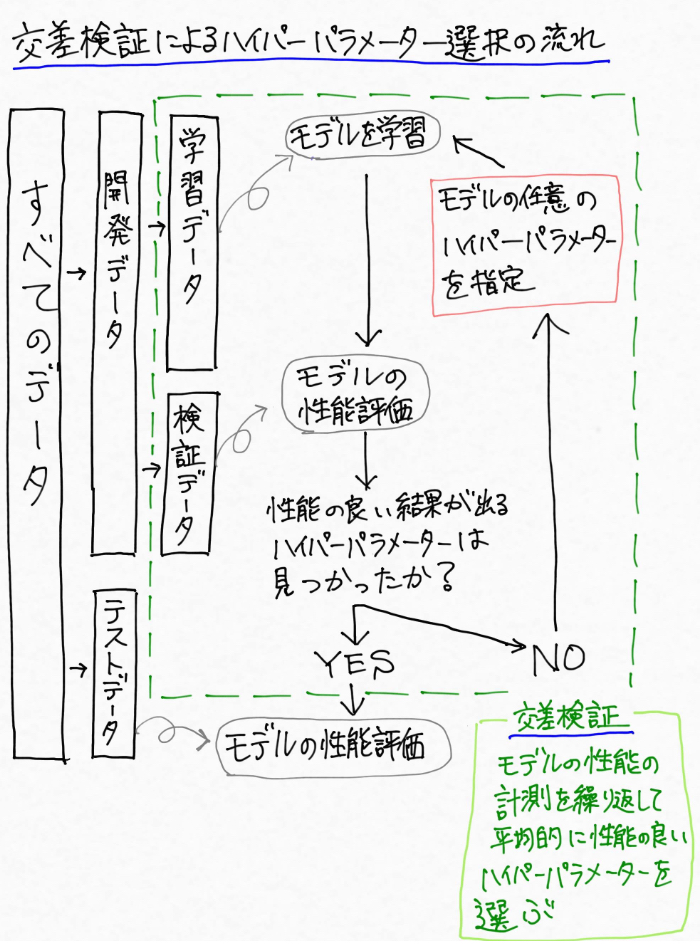
ふう。。なんとかここまで整理できました(これは個人的に、僕の頭では整理することがマジで大変でした 汗)。
過学習の対策の一つに、「ハイパーパラメーターを調整する(モデルを簡単なものにする)」がある。
ハイパーパラメーターとは、機械学習のモデルが持つ人が調整をしないといけないパラメーター(決定木の深さなど)のことを言い、調整することでモデルの複雑さを軽減できる。ハイパーパラメーターは交差検証という方法を用いて繰り返し検証しながら調整していくことが必要である。
様々ある交差検証の種類については以下でまとめています。興味のある方はこちらもどうぞ。

過学習への対策その3:正則化を実施する
①学習(訓練)データの数を増やす
②ハイパーパラメーターを調整する(モデルを簡単なものにする)
③正則化を実施する
ようやくここまできた・・・。今回のラスボスなので改めて気を引き締めて取り組んでいきます!
正則化とは、モデルの動きに制限をかけるもの〜身体でいうとギプスに似たイメージ
そもそも「正則化」ってなに?となったので調べていくと、
「過学習を防ぐためのテクニック」とのこと。
で、「具体的にこれは何をしているんじゃい?」と掘り下げながら理解していきます。
ここで一旦復習もかねて、、、
改めて、データの傾向やパターンを掴んで未知のデータの予測や判定を行うのが機械学習。そして様々な種類がある機械学習アルゴリズム(機械学習の方法)に基づいて、データの傾向やパターンを掴むモデルが構築されていく。
これまで何度も登場していきているこのモデル。これまではずっと視覚的に直感でわかるように表現してきましたが、結局はy=ax+bみたいな数式で表現可能です。
ようやくここまでたどり着いたんですが「正則化」とは、簡単に言うと数式で表されるモデルに「正則化項」というものを罰則として足し算することで、モデルの形が複雑になりすぎないように調整しようというものです。
初めはこの説明では誰だって?????となります 汗
あくまでイメージですが、、、
私たちは、身体を関節で折り曲げして身体を複雑に動かすことができますよね。けれど怪我をして体にギプスを装着すれば、制限がかかって身体を複雑に動かすことはできないので、動作がずっとシンプルになります。
こんな風に身体(モデル)にギプス(正則化項)というものをつけて、モデルの動きをシンプルにしようとするのが正則化です。
ギプスのことを僕は28年間「ギブス」と呼んできましたが、これは間違った呼び名らしいですね 汗
そして、情報を集めていてわかったのは、教師あり学習における「回帰」と「分類」では、少しだけ正則化が作用するイメージが違うということでした。(過学習を防いで汎化性能を高める!という意味ではもちろん一緒)
そこで以降では、「回帰」と「分類」の場合で分けて正則化について整理していくことにします。
過学習を防いで汎化性能を高めるためのテクニックの一つに「正則化」がある。正則化は、数式で表されるモデルに「正則化項」というものを付けることで、モデルの形が複雑になりすぎないように調整しようとするもの。
教師あり学習(回帰)の場合、正則化はこうやって働く
 ここからは、過学習を防いで汎化性能を高めるためのテクニック「正則化」が、教師あり学習(回帰)の場合はどのように作用するかを具体的に見ていきます。
ここからは、過学習を防いで汎化性能を高めるためのテクニック「正則化」が、教師あり学習(回帰)の場合はどのように作用するかを具体的に見ていきます。
教師あり学習(回帰)とは、正解となる数値(例えば過去の売り上げ)と入力データ(例えば天気や気温など)の組み合わせで学習し(売り上げのパターンをつかみ)、未知のデータ(未来の天気や気温などの情報)から連続値(未来の売り上げ)を予測する手法です。
例えば、不動産を探している時に機械学習を用いて、駅からの距離と家賃の関係を表すモデルを作りたい場合を考えてみる。
正則化が弱すぎると右端のように学習データに対して必要以上に適合した線、つまり過学習状態になってしまう。
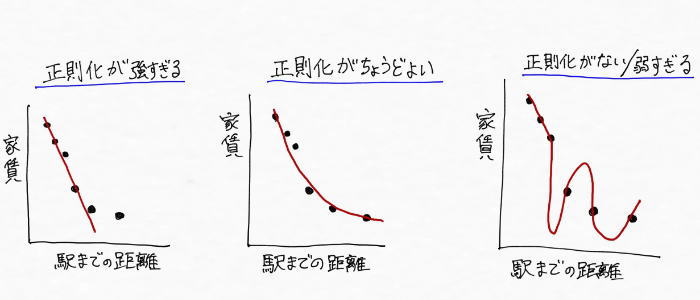
それに対して、正則化が強すぎれば、今度は学習データの特性を大雑把にしか掴めなくなる(身体をギプスでガチガチに固められたようなイメージ)ため左端のようになってしまいます。
なので、真ん中の図のように適切な強さで正則化を実施することで過学習を防いで汎化性能を高めることが大事というわけです(^^)
こんな風に教師あり学習(回帰)の場合、正則化は強弱によってモデルを複雑な形にしたり、簡単な形にすることができる。適切な強度で正則化を実施することが必要。
教師あり学習(分類)の場合、正則化はこうやって働く
 次は「正則化」が教師あり学習(分類)の場合はどのように作用するかを具体的に見ていきます!
次は「正則化」が教師あり学習(分類)の場合はどのように作用するかを具体的に見ていきます!
教師あり学習(分類)とは、「正解となる離散的なカテゴリ(例えば秋田犬、とか犬の名前)と入力データ(犬の画像)の組み合わせで学習し(犬の画像と名前のパターンをつかみ)、未知のデータ(名前のわからない犬の画像)からクラス(犬の名前)を予測する手法です。
教師あり学習(分類)の場合における「正則化」による作用のイメージは、極端な例えをすれば、「一つも間違いは許さんぞコラ!」という完璧主義ガチガチの考え方を、「少しぐらい間違いも許容するよ〜」というゆるーい考え方にしていく感じです。
もう少し詳しく専門的にいうと、例えば2つのクラス(カテゴリ)を分類する境界を、全データが正しく別れるようにきっちり設定するのではなく、多少違うクラスのデータが混ざってもいいから未知データに対する対応力を付けるというものです。
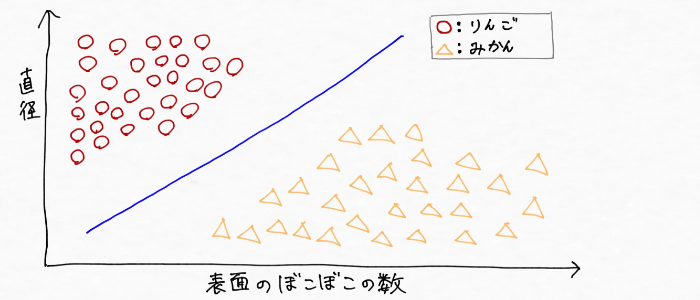
もっともっと具体的にみていくために、AI(機械学習)を用いてリンゴとミカンを分類したい場合を考えてみる。
実際はどうなるかわからない(僕が勝手に書いたイメージだから)けど、「直径」と「表面のぼこぼこの数」という二つの特徴から、りんごとみかんのデータを取って、仮に下図のようにデータがとれたとする。

この時、次のように線を引くことでりんごとみかんが分類できそうです。
けれど、もしリンゴとミカンのデータの記し方を人が間違えたり、突然変異で普通ではありえない外見をしたみかんが一つ収穫できてこんな風にデータが取れて分類したとする。
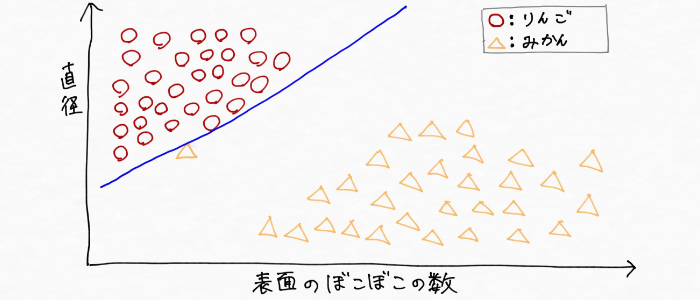
この分け方だと、まだ収穫できていないもっと小さなりんごなど(未知のデータ)を、うまく分類できないモデルになってしまいます。つまり、既存の「学習データに対してだけ分類できるモデル」という過学習状態になってしまう。
リンゴとミカンを精度高く分類できるモデルを構築するためにはこんな極端な線の引き方ではダメで、最初の図のような(汎化性能が高い)境界線を引くモデルが必要です。つまり、突然変異で普通ではありえないようなみかんに影響され過ぎることを防ぐ役割をするのが「正則化」です。
言い換えれば、「正則化」を実施することで既知の学習データの影響を受けすぎないようにしているというわけ。
教師あり学習(分類)の場合、正則化は学習データの影響を受けすぎないようにし、大雑把にでもいいから分類しようという作用をもたらします。

まとめ
 さて、今回はAI(機械学習)を実装しようとする際によくある問題、過学習とはどういうもので、どう対策したらいいのかについて見てきました!!改めてここまでを整理すると以下のことがわかりました!
さて、今回はAI(機械学習)を実装しようとする際によくある問題、過学習とはどういうもので、どう対策したらいいのかについて見てきました!!改めてここまでを整理すると以下のことがわかりました!
- 過学習とは、学習データに対してはきちんと正解できるけど、未知のデータに対しては全然当たらないモデルの状態のことを言う。過剰適合、Over Fitting(オーバーフィッティング)と呼ばれることもある。
- 未知のデータにも対応できるモデルを「汎化性能(汎化能力)があるモデル」と言う
- 過学習対策1:学習(訓練)データの数を増やす
→データの数を増やすことで、よりデータの傾向がより掴みやすくなり、汎化性能を高められる - 過学習対策2:ハイパーパラメーターを調整する(モデルを簡単なものにする)
→機械学習のモデルには、モデルの複雑さを調整する「ハイパーパラメーター」と呼ばれるパラメーター(変数)があり、交差検証と呼ばれる方法を用いて適切なハイパーパラメーターを決定することで汎化性能を高められる。 - 過学習対策3:正則化を実施する
→正則化を実施することで、モデルが複雑になりすぎることを防ぎ、汎化性能を高められる
今回過学習に対する理解を深めてきて、こんな風に学びを深めていくことは楽しいものだと改めて実感。
しかし注意したいのが、僕の場合はAI(機械学習)エンジニアとして活動していくことが目的なのに、ついついAI(機械学習)を学ぶことが目的になってしまいがちだってことです 汗
趣味だったり、好奇心を満たすことが目的ならそれはそれで素晴らしいんだけど、実際に活用・応用したいなら「学んだけど使えません」っていう状態では流石に落ち込んでしまいます。(実際僕はそんな状況に陥って落ち込みました、左遷もされたし・・・)
今回過学習について整理したことを、自分の実生活に例えてみれば、、、
- 過学習→学ぶだけで実戦で使えない状態
- 汎化性能がある→学んだ知識を実務で実践できる(ここを現在目指しているんだ僕は!)
- 学習データの数を増やす→偏りすぎず幅広く知識を入れる
- 交差検証を用いてハイパーパラメーターを調整する→学び方を色々試してみてベストな方法を見つける
- 正則化を実施する→失敗を怖れずシンプルに考えてまず行動する
と言える。。。
こんな風に実生活に落とし込めたように、AI(機械学習)について学びを深めているのに毎回分野を超えた大事な学びを得ているような気がします。
「目的を見失わずあくまで知識を使うために学んでいるということを忘れるなよ!」というメッセージも今回のコンテンツ作りを通じて僕の頭へ降ってきました。何をするにしても、全体を俯瞰しながら目的を忘れずに行動していきたいものですよね(^^)
次回は「モデルの性能評価」について理解を深めていく予定です!興味のある方は次回もまた見にきてくれるととっても嬉しいです!!
<参考>
・Andreas C. Muller and Sarah Guido (2016). Introduction to Machine Learning with Python: A Guide for Data Scientists. O’Reilly Media, Inc. (アンドレアス・C・ミューラー、サラ・グイド 中田 秀基(訳)(2017). Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎 株式会社オライリー・ジャパン)
・Sebastian Raschka(2015). Python Machine Learning. Packt Publishing. (株式会社クイープ、福島真太朗(訳)) (2016). 『Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)』

AI(人工知能)って「なにそれ美味しいの?」ってレベルだった僕が、AIエンジニアを目指してステップを踏んだり踏まれたりしている記事を書いてます。よかったら読んでみてください(実話)。



コメントをどうぞ
講義の復習として、難解な数式ではなく概念から体系的に学べる場所を探していたのでぴったりなサイトに出会えて大変嬉しいです。
文章や図が非常に整理されていてかつ具体性もあって内容がスッと頭に入ってきました。とても分かりやすい!!
今後も基本から振り返りたい時などありがたく利用させていただきます。
つっちーさんこれからも頑張ってください。応援しています。
読んでいて楽しいです!独学していて、やる気が出なくなった時に、使わせて頂いてます
交差検証を使えば全ての犬の画像が必ず一度はテストデータとして利用されます。
⇒ これは
交差検証を使えば全ての犬の画像が必ず一度は検証データとして利用されます。
の誤りでは
匿名さん、ご指摘ありがとうございます。仰られた通りですので修正いたします。失礼しました。
機械学習初心者です。テストデータ:未知のデータ、まだ手元にはない未来のデータ、とあるのですが未知のデータなのに青色でプロットできてるのはなんででしょうか?ご回答よろしくお願いします。
のりさん、質問頂いた件ですが、過学習に陥った場合にはモデルがテストデータに全然適合できていないことをよりイメージしやすいようにプロットしております。
ご指摘の通り、手元にないデータですので本来はプロットできませんが・・・。
わかりやすすぎですね、このサイト