
AIブームの熱にアチチアチチとなっているご時世ですから、AI(人工知能)を実現する技術である機械学習というワードはよく見聞きするものでご存知の方も多いことでしょう。しかし「半教師あり学習」というワードに出会う機会はそれに比べてずっと少なく、知っている方はかなり少ないのかもしれません。
実際、今みなさんがご覧になっているこのメディアAIZINEでは「半教師あり学習」というテーマで書いた記事はまだありませんし(実際に調べました)、機械学習の参考書に目を通していても中々登場しないワードです。
しかしAI(機械学習)エンジニアを目指している僕は、機械学習の腕を競い合ったりプロのコードを見て学べる場である「Kaggle」に取り組んでいて、最近「半教師あり学習」とやらに出会いました。半教師あり学習の存在は知っていたけれど別に知らなくても困らなかったので特に調べもしていませんでしたが(おいおい・・・)、知らないといよいよ困る状況になってきたわけです(僕が)。
そこで今回は、この謎の「半教師あり学習」について調べてみることにしました!
——————-補足———————-
※機械学習:AI(人工知能)を実現する技術の一つ。データからそのデータに潜むパターンや傾向を見つけ、見つけたパターンや傾向を元に未知のデータに対しても判定や予測を行っていく技術
※Kaggle:世界中のデータサイエンス・機械学習に携わる人が参加するコミュニティーサイト。世界中の企業から提供されているデータを機械学習を利用してデータ分析の腕を競い合う。機械学習のプロたちの知見を誰でも無料で得られる
そもそも半教師あり学習は機械学習においてどこに位置するのか?
機械学習に関わる技術には様々なものがありますが、書籍『未来IT図解 これからのAIビジネス』で掲載されている機械学習に関わる技術を示した下の図によると、半教師あり学習は教師あり学習と教師なし学習の重なる領域に位置しています。
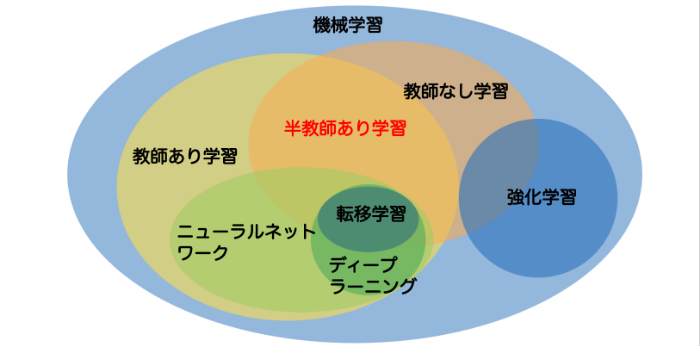
※古い研究の歴史がある機械学習を分類する考え方にも様々ありますが、ここでは大きく教師ありと教師なしの観点で分けています
念のため補足ですが「教師あり学習」とは、情報とその正しい答え(ラベル)をセットにしてコンピュータにデータのパターンを掴ませていく手法で、「教師なし学習」とは予測や判定の対象となる正解ラベル(教師)なしでデータから共通する特徴を持つグループを見つけたり(クラスタリング)、データを特徴づける情報を抽出したりする手法(PCAなど)のことを言います。
※ラベルがあるデータ:正解が付与されているデータ
※ラベルが無いデータ:正解が付与されていないデータ
半教師あり学習とは一言で言うと何なのか?

さて、前置きはもう止めにして結論からいくと半教師あり学習とは、
少量のラベルありデータを用いることで大量のラベルなしデータをより学習に活かせることができる学習方法です。
文字だけだとイメージしづらいですが、半教師あり学習は人間の学習ととても似ています。例えば僕たちは「おぎゃあっ」と生まれてからしばらくは、様々なものの名前を教えてもらわずにただ見ているだけです。そして成長してコミュニケーションが取れるようになってくると様々なもののラベル(例えば「これはネコ」「これはイヌ」)を他人から与えられ、後は自分でたくさんのネコやイヌを見てどんどん学習して認識できるようになっていきます。
これと同じように、少量のラベルありデータを用いることで大量のラベルなしデータを活かして学習していける、というものが半教師あり学習です。
半教師あり学習のメリットデメリットは?

光あるところには必ず影があるように、半教師あり学習にも当然ながら様々なメリットとデメリットがあります。
<メリット>
- ラベルありデータとラベルなしデータの両方を使って学習ができるため、学習データが不足しているときに有効活用できる可能性がある
- 大量のデータにラベルを付与してラベルありデータを作るという作業を軽減できる
<デメリット>
- 高い確信度で予測して擬似ラベルを付与しても、実際の答えが違っている場合には間違ったデータで学習することになる
- ラベルありデータに偏りがあると上手くモデルが学習できなくなってしまう
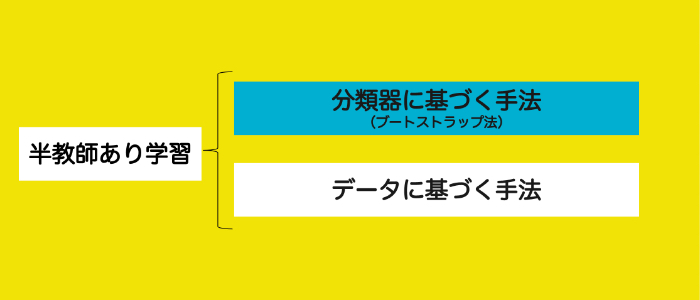
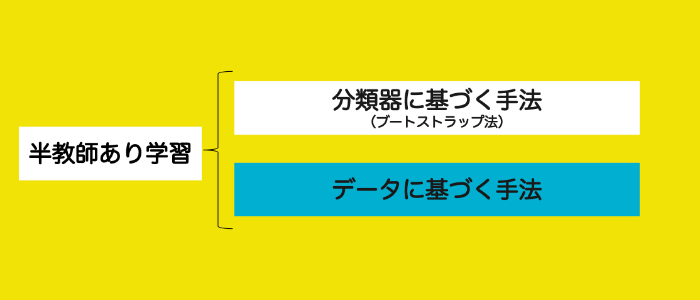
さて、こうしたメリットデメリットのある半教師あり学習ですが、半教師あり学習の手法は大きく次の二つに分かれます。
- ブートストラップ法(分類器に基づく手法)
- データに基づく手法
以降ではこれらの手法について順番に見ていきましょう。
分類器に基づく手法(ブートストラップ法)
半教師あり学習の一つ目の手法の分類器に基づく手法(ブートストラップ法)は、学習した分類学習器(※)を用いてラベルなしデータの推論を行い、高い確信度で推論した結果をラベルありデータに追加して学習を進めていく手法です。
※学習した分類学習器:アルゴリズムによってデータから獲得されたパターンやルールを数式的に表現したものをモデルと言いますが、変数を微調整するなどしてデータからパターンやルールを掴んでより適切に表現した(学習した)モデルを「学習した分類器」と言います
少しわかりにくいですが、これはクロスワードパズルのイメージに近いかもしれません。クロスワードパズルは今わかっている情報から正解を予測して、予測した結果(ワード)が正しいという仮定に基づいてまた次の正解(ワード)を予測していきます。この繰り返しをすることでどんどん穴が埋まってくゲームでしたね。
半教師あり学習でも同じように、まずは正解がわかっているラベルありデータから学習して学習済の分類器を作り、次はその分類器が「これは間違いないでしょ!」と高い確信度で予測した擬似的な正解ラベルをラベルなしデータに付与し、それらを訓練データに追加します。半教師あり学習ではこの工程を繰り返します。
つまり、ラベルなしデータに対してラベルを付与して、どんどん訓練データを増やしながら自ら学習していくというのが半教師あり学習における分類器に基づく手法(ブートストラップ法)なんですね!(なるほど!)
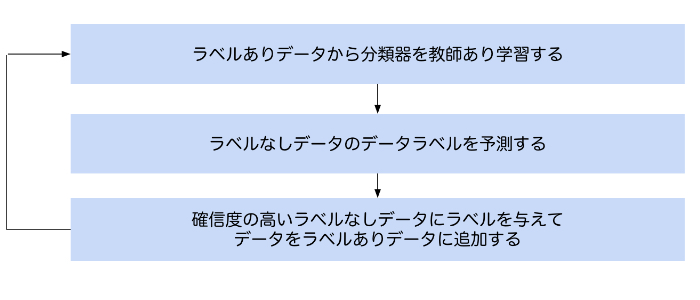
分類器に基づく手法(ブートストラップ法)の基本的な処理の流れは次の通りです。
- ラベルありデータから分類器を教師あり学習する
- 作成した分類器を使ってラベルなしデータのラベルを予測する
- ラベルなしデータと予測結果(擬似的な正解ラベル)をセットにして、ラベルありデータに追加する(例えば99%以上の確率でこの予測結果は間違いないだろう!のような高い信頼度の分類結果が出たデータをラベルありデータに追加する)
- 以上を繰り返す
これを図にすると次のようになります。
このようなブートストラップ法ですが、様々な種類があります。代表的なものについて整理しました。
分類器に基づく手法(ブートストラップ法)その1:自己訓練(Self Training)

前述した流れがまさに自己訓練(Self Training)と呼ばれる手法で、ある一つの分類器(教師あり学習)を使ってラベルありデータのみで学習し、ラベルなしデータの分類をします。その後分類したラベルなしデータのうち高い 確信度 で分類できたものは正しいと考え(正しい予測をしたと考え)、ラベルありデータとみなして再度学習します。これの繰り返しを行うのが自己訓練(Self Training)です。
分類器に基づく手法(ブートストラップ法)その2:共訓練(Co-Training)

自己訓練(Self Training)では予測結果の信頼度に基づいて教師なしデータに対してラベルを付与していくわけですが、もしも予測結果が実際のものと異なっていたらおかしなことになります。クロスワードパズルを解いていて、入れるワードを間違えばその次に入れていくワードもどんどん正解から離れていき、決して正しいものにはなりません。
自己訓練(Self Training)による誤りを100%無くすということはできませんが、このような問題を少しでも改善しようという目的から生まれたのが共訓練(Co-Training)と呼ばれる手法です。
共訓練(Co-Training)の処理の基本的な流れはSelf Trainingと同じですが、共訓練(Co-Training)の基本的な考え方は、異なった視点を持つ2つの分類器を作成してお互いの分類器が持つ情報を交互に補間し合うことでより良い学習を目指すというものです。
共訓練(Co-Training)では上図のように異なる分類器を2つ使うのが特徴で、次の流れで処理を進めていきます。
- ラベルありデータを分割(特徴量を分割)して、分類器1と分類器2でそれぞれ学習する
- ラベルなしデータをそれぞれの分類器で分類する
- 分類器1の確信度上位k個を分類器2のラベルありデータに追加
- 分類器2の確信度上位k個を分類器1のラベルありデータに追加
- 上記を繰り返す
文章だけではわかりにくいので処理の流れ図で確認してみましょう。
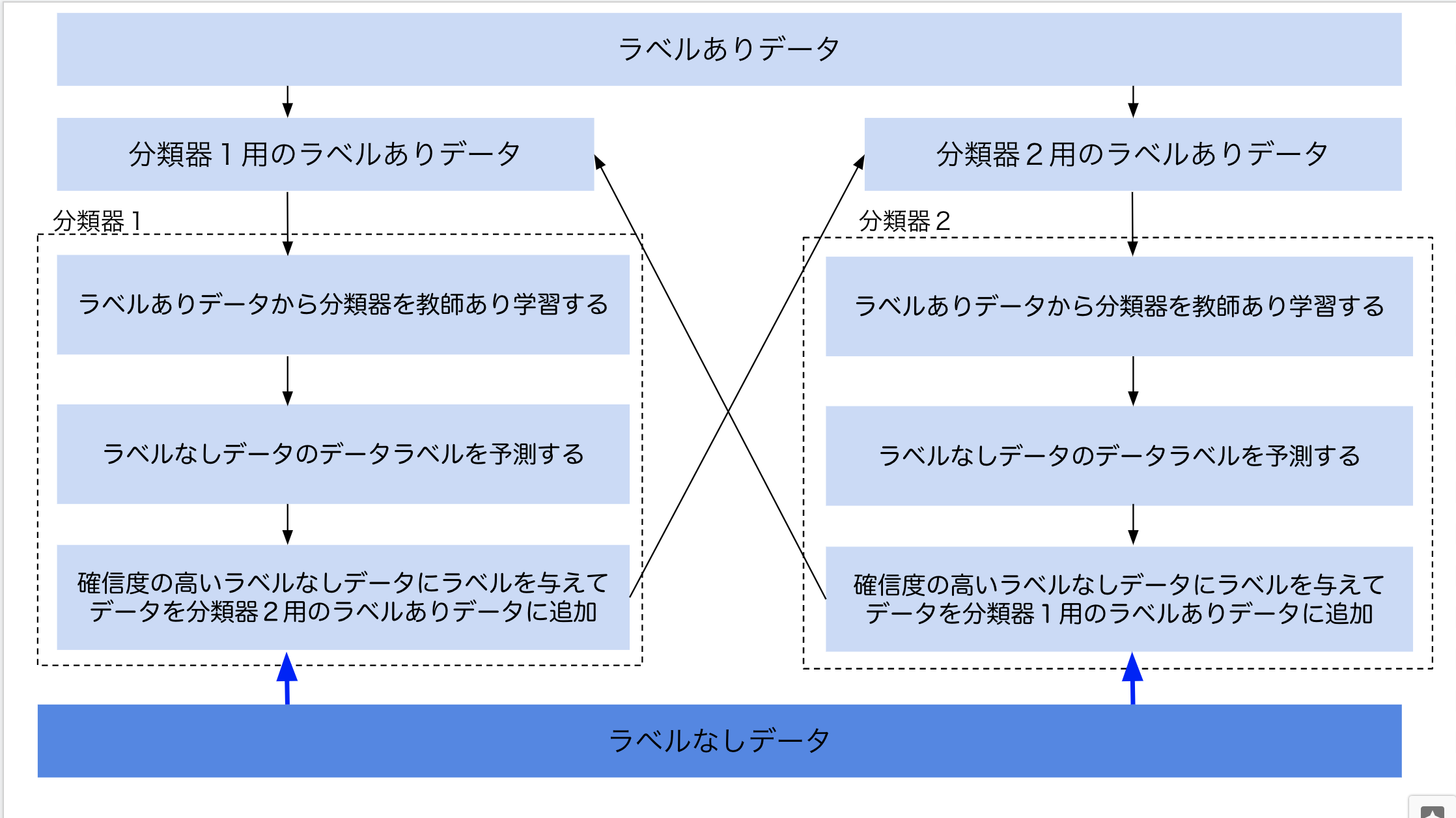
このように共訓練(Co-Training)は複数の分類器を組み合わせることによって分類器の性能を向上させようとするものです。
データに基づく手法
半教師あり学習の2つ目の手法は、ラベルなしデータからデータの表現方法、分布を獲得してそれを用いて教師あり学習を行う方法です。この方法に該当するグラフベースアルゴリズムは、データの分布を元にグループ分けする分類法で、「近くにあるから同じラベルのはずだ」とデータ同士の近さを考えてラベルありデータからラベルなしデータにラベルを伝播していきます。
データがどれだけ近いかを判断の基準にしているアルゴリズムには様々あり、半教師ありk近傍法、半教師あり混合分布モデル、半教師ありSVMなどタイプも様々ですが本記事では一番基本的な手法でわかりやすい(僕自身が理解できた)k近傍法を紹介しましょう。
半教師ありk近傍法グラフ
半教師ありk近傍法グラフは、あるラベルありデータから同心円を描いて、その円内に入るラベルなしデータに同じラベルを付与するというものです。図で確認してみると、次のようにラベルありデータ(青と緑)を中心にラベルなしデータ(黒)がk個(この例ではk=3)含まれる円を描き、その円内に含まれたラベルなしデータ(黒)を同じラベルとします。
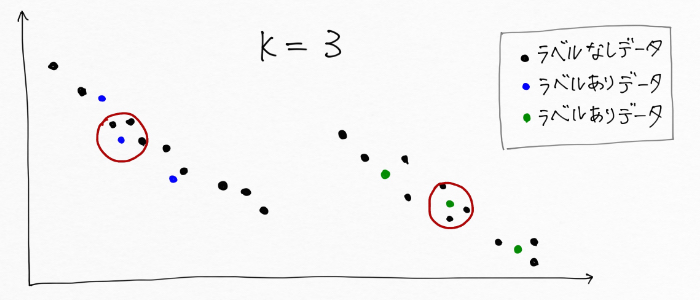
この処理を繰り返して次々とラベルを付けていくわけです。
半教師あり学習の事例

半教師あり学習が使われている身近な事例には、Google Photosのような一部の画像ホスティングサービスが挙げられます。実際に利用されている方も多いことでしょう。ご存知の方も多いと思いますが、Google Photosでは人物の写真をアップロードすると、自動的にAさんが写真3、5、7に写っていて、Bさんは写真2、4、6に写っている、そしてCさんは、、、ということが認識されます(もちろん間違った認識をされることもあります)。
その後、サービスからの質問に沿って一人について一つずつこの人物は誰なのか?というラベルを提供して上げることで、写真に写っている人物全員が誰なのかが自動で認識されるようになります。
また、最近ではディープラーニング(Deep Learning)の構造をうまく利用した様々な半教師あり学習の手法も提案されてきているため、データへのラベル付与などの学習データ整備の手間が少なくなってディープラーニング(Deep Learning)導入の障壁がどんどん低くなっている影響もあるようです。
知らず知らずのうちに私たちは半教師あり学習の恩恵を受けているのですね(^^)
まとめ

さて、今回は半教師あり学習について整理してきました。振り返ってみると、
半教師あり学習とは少量のラベルありデータを用いることで大量のラベルなしデータをより学習に活かせることができる機械学習手法であり、分類器に基づく手法(ブートストラップ法)とデータに基づく手法の二つに大別されました。そしてそれぞれについても様々な種類の手法があることがわかりました!
今回まとめてみた半教師あり学習は、日本語での情報がまだまだ少なかったり、難解な用語や数式を使った説明が多く整理するのには非常に苦労しました 汗。そんなこともあって、わかりやすい参考書、翻訳書が出ることを期待します(個人的に)。。
ここまで半教師あり学習の基本的なことを整理してきましたが、インプットはアウトプットがあって初めて活かされるものですので、今回整理したことは基礎知識として持っておきながらKaggleなどで自分で使ってみるなど手を動かして、どんどん使える知識へと昇華して行きたいですね!
・Ladder Netwoksによる半教師あり学習
・半教師あり学習 チュートリアル
AI(人工知能)って「なにそれ美味しいの?」ってレベルだった僕が、AIエンジニアを目指してステップを踏んだり踏まれたりしている記事を書いてます。よかったら読んでみてください(実話)。



コメントをどうぞ